

Whether you're a burgeoning content creator or a business scaling its online presence, mastering YouTube Analytics is key to propelling your channel's growth. As outlined in this insightful article by Hootsuite, for example, leveraging this robust tool can unlock profound growth opportunities. But here's a question that often gets overlooked: What happens when your platform diversity grows and the need for a consolidated data view becomes imperative? Juggling insights from multiple sources can become a complex challenge, and that's precisely where integrating with a database like MySQL changes the game. It's not just about storing large volumes of data—it's about centralizing your analytics to obtain a panoramic view of your performance, trends, and areas ripe for expansion. So, how do you bridge the gap between YouTube Analytics and MySQL? Dive into our guide that simplifies this integration into three manageable steps, ensuring your data works as hard as you do in building your digital empire.
Although there are many relational databases, we chose MySQL for this article in particular as it is one of the most popular open-source database management systems. For more information on MySQL itself, take a look at MySQL's documentation.
Databases allow you to organize and structure your data so that you can easily access, manage, and transform it. Most databases use SQL, the standard language for relational database management systems, for writing and querying data.
So, how can you insert your YouTube Analytics data into MySQL? In this article, we are going to show you three different methods. If you wish to skip to the part we called “3 Simple Steps,” jump straight to the last section of this article.
1. Insert YouTube Data Manually
We’re going to be upfront about this—manual insertion of your data is not recommended for numerous reasons which we will go over later. Nevertheless, if you are just starting your channel out and don’t have a lot of experience with MySQL or you are not a data engineer, this method will suffice, albeit not long-term if you plan on growing. Also, it never hurts to know the basics. Let’s get started!
(If you already know about the dangers of manual data extraction, go ahead and skip to automatized data pipelines!)
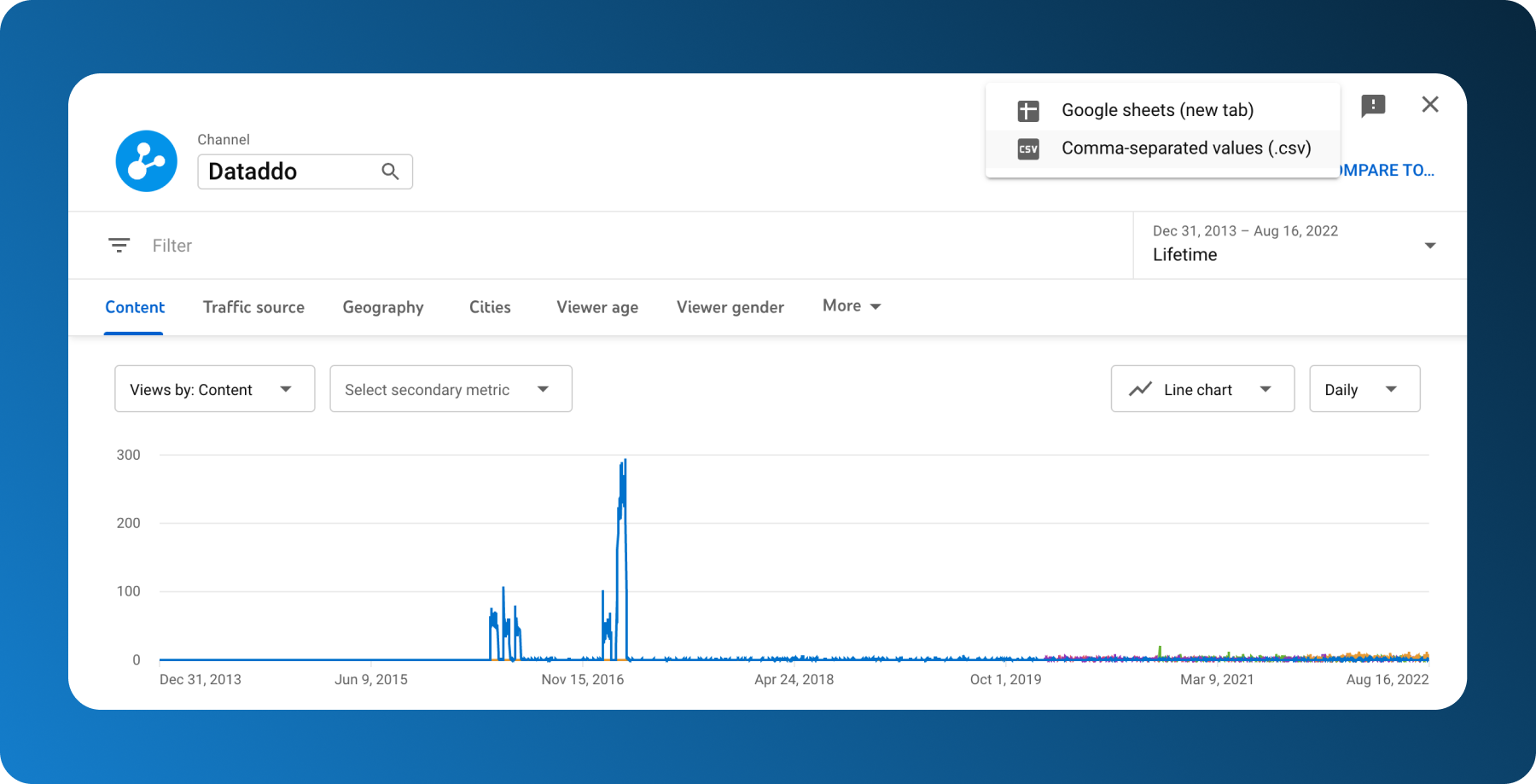
Step 1: Download YouTube Analytics Data
Head over to your Creator Studio and in the left menu click on Analytics and download your table from the top right corner. Since we’re going to be loading the table to MySQL right away, download the CSV file so you don’t have to download the table from Google Sheets again.
Repeat step one as many times as needed for the other tables.
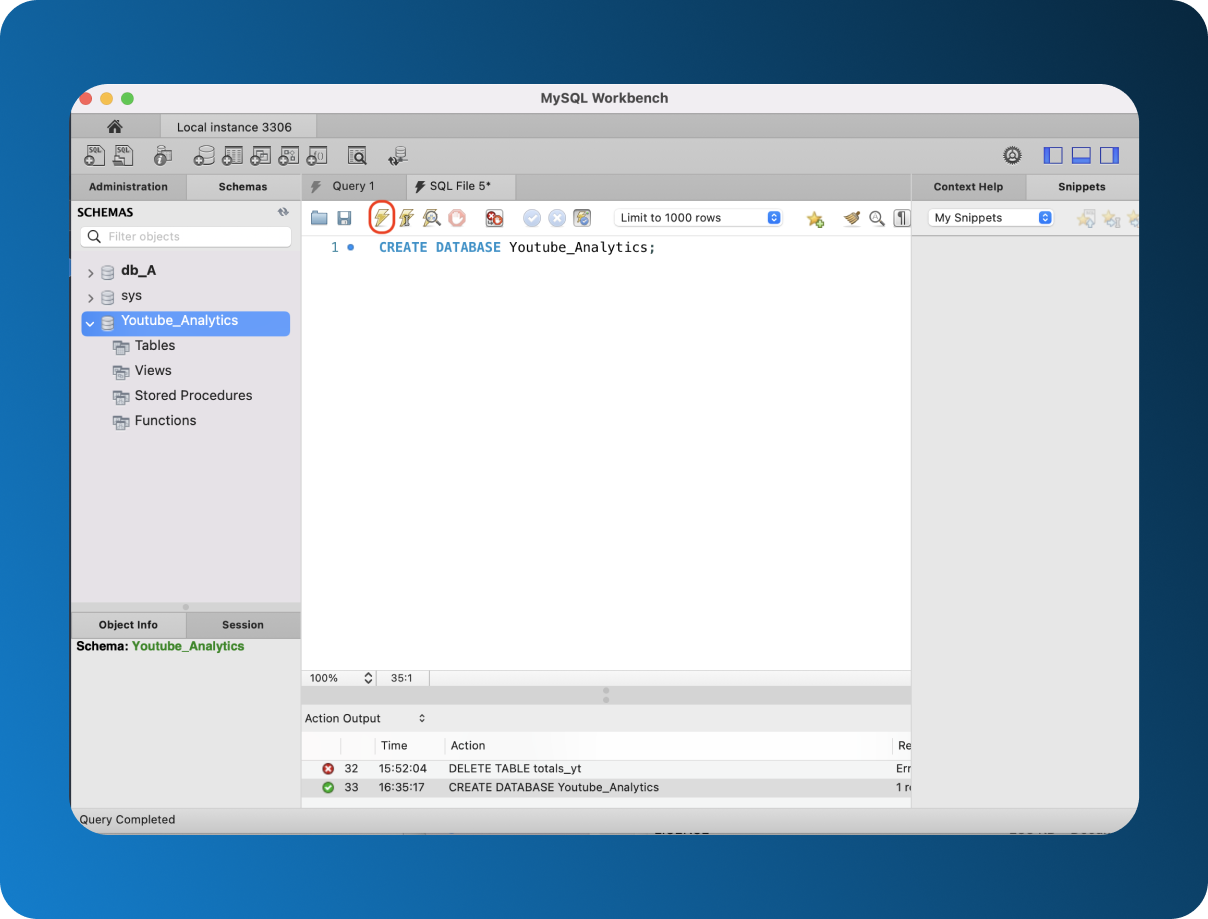
Step 2: Create a Database in MySQL
Open MySQL workbench and start with creating a database. Type
CREATE DATABASE database_name;
and click on the lightning bolt symbol to execute the action. In the Action Output, you can see whether your command was successful or not.
If you can’t see your database under Schemas, simply refresh it for your database to show up.
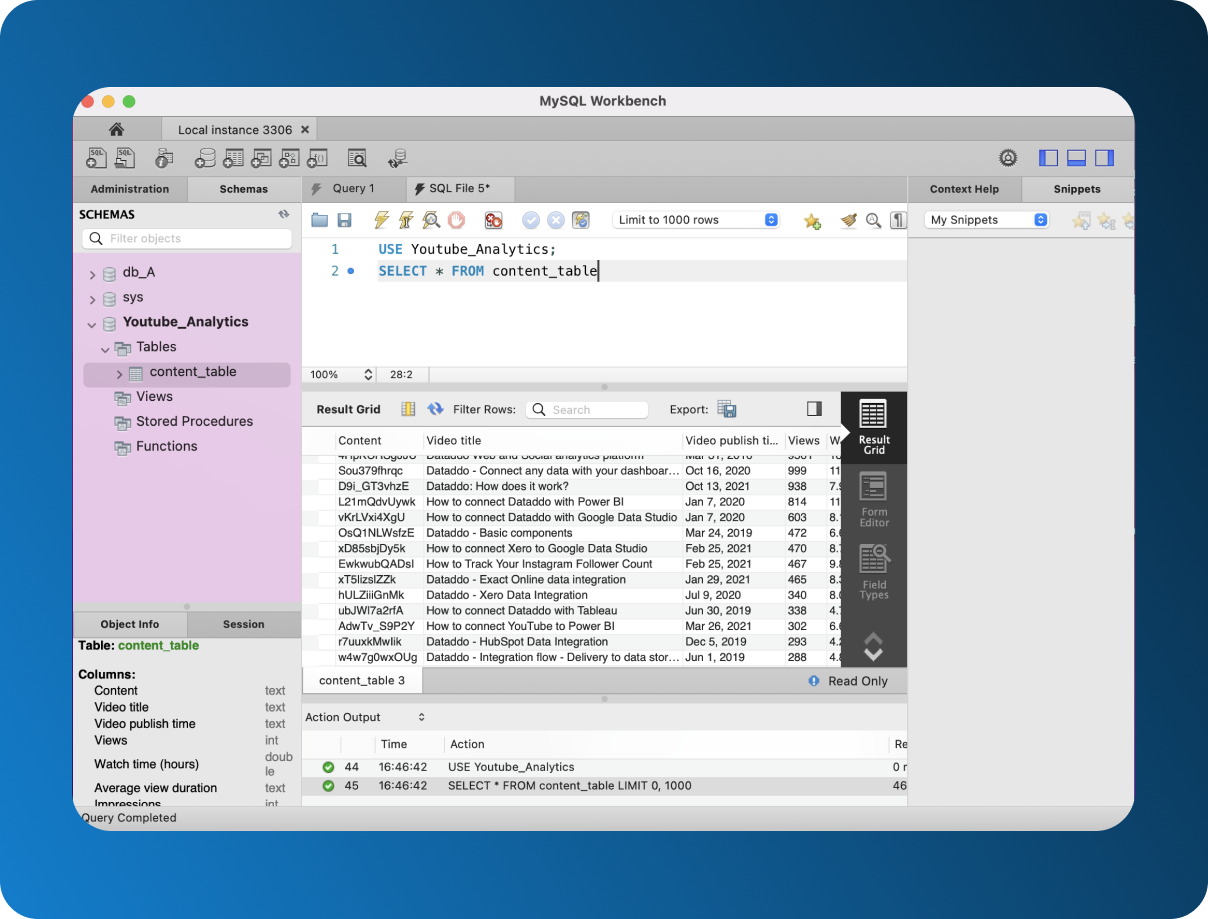
Step 3: Load Your Table
In your newly created database, right-click Tables and choose Table Data Import Wizard.
Follow the prompts to choose file Table data from the .zip file you downloaded from YouTube Analytics.
(Optional) Step 4: View Your Table
To view what you imported, first select your database by writing:
USE database_name;
And to select the table write:
SELECT * FROM table_name;
The star suggests you want to select the whole table. Click on the lightning bolt again to execute your query.
Manual Extract, Load, Transform (ELT) Pitfalls
So why is manual data extraction and insertion not our preferred method? If you have just one or two tables, it might be doable but once you start working with more data sources, there’s a lot of space for error. Here are some of the main disadvantages:
Extremely Time-Consuming: If you want to download all YouTube Analytics data and you have two YouTube channels, you will need to repeat the whole process (except for creating a new database) a whopping 58 times. This will take up the time which could have been dedicated to data analysis instead.
Expensive: Manual data load will eventually become so demanding that there will need to be someone dedicated to data extraction and loading. The result? Extra expenses.
Prone to Error: With more than 1 table, you always risk downloading and/or inserting something twice by mistake, or worse, forgetting to insert a table altogether and losing an important chunk of data, creating a havoc.
Forget Scalability: Even on a weekly basis this process would be extremely tedious, what would it look like if you needed to update your data on a daily basis? We also assume you plan to grow, which means you will eventually have to start using more tools. How many work hours would need to be spent on data extraction alone?
Working with Real-Time Data? Not Likely: By the time you finish extracting your data, new data was already generated. If you are manually extracting, loading, and we also assume transforming data, you can just dismiss the idea of working with real-time data altogether.
In today’s day and age, there is simply no reason to do ETL or ELT manually. We will go over other methods, but if you are not a data engineer who can build a custom data pipeline, skip to section B—connect data using our no-code data integration tool, Dataddo.
2. Set Up Data Pipelines
The alternative to manual data loading is, of course, setting up automatized data pipelines. With data pipelines, you avoid most if not all of the pitfalls that come with the previous method. Once set up, data pipelines will ensure a secure and steady flow of data that can also scale together with the business.
We will try to outline the positives and negatives of the two most common ways for you to decide which fits your and your organization’s needs the best.
A. Write a Custom Script
One of the greatest advantages of custom connections is that they are tailor-made in-house for your business. Once set up, they will save you a lot of time and effort.
However, this method is not foolproof. Data pipelines often break, e.g. due to changing APIs, which is why there is a need for a data engineer who will monitor them. While in the long-term, custom integration is time-saving, it might not be entirely cost-effective.
To learn more about building your own data pipeline check out this Medium article. Or if API changes are your main concern take a look at Dataddo Headless, a single API for all your integrations.
B. From YouTube to MySQL With Dataddo in 3 Simple Steps
Last but not least, you can connect your data with an ETL tool such as Dataddo.
Before we start: Create Your Database in MySQL
Open MySQL workbench and type
CREATE DATABASE database_name;
Click on the lightning bolt symbol to execute the command, and refresh your Schemas to see the newly created database.
Create Your Source
Now we can head onto the data pipeline itself. First, click on Create a Source (in your homepage or under Sources tab) and select your connector—YouTube Analytics.
Select your metrics and attributes.
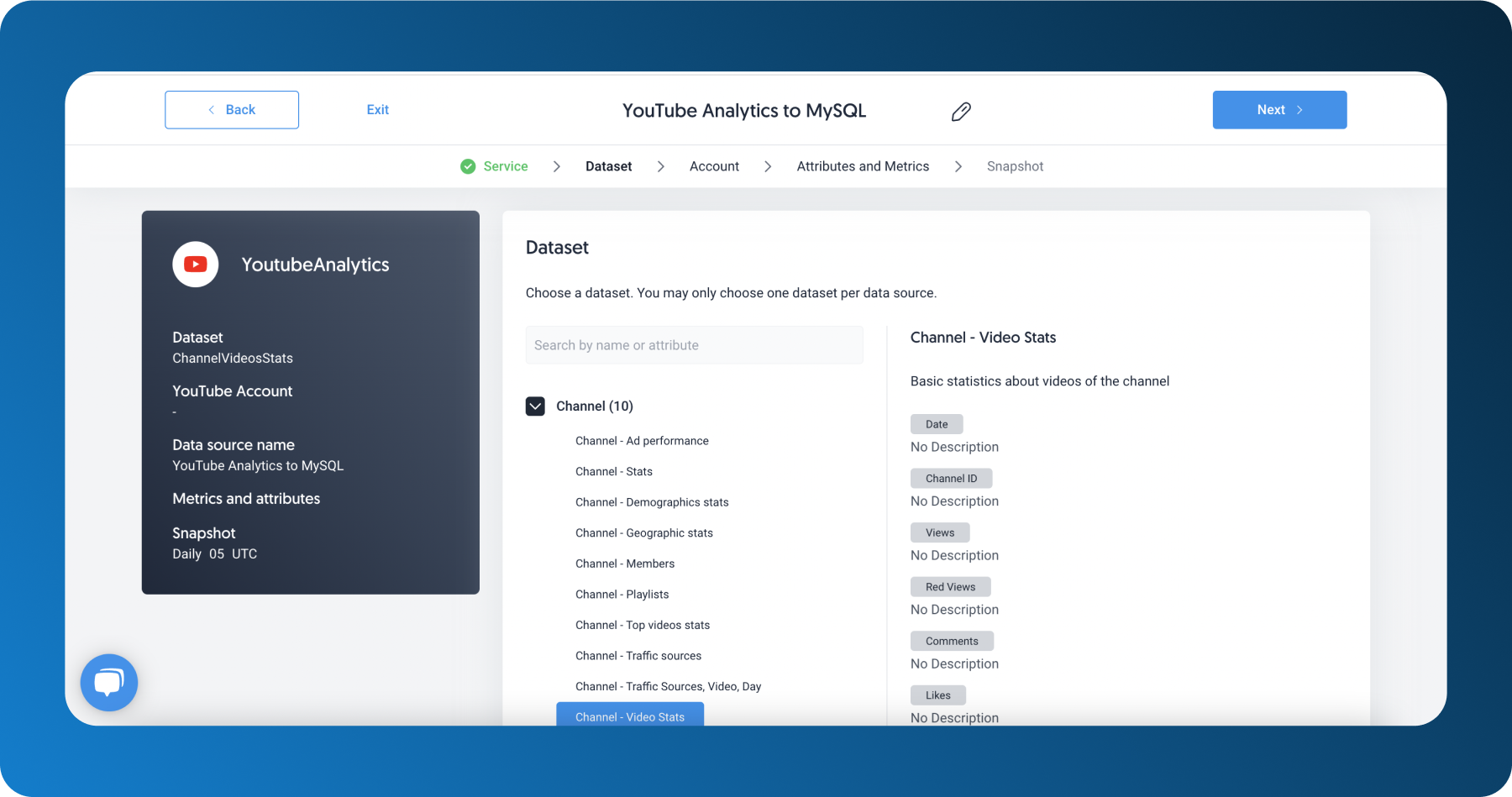
In the next step, select which YouTube account and which channel you will be pulling data from and choose how often you want your data to be synchronized. Finally, preview your data.
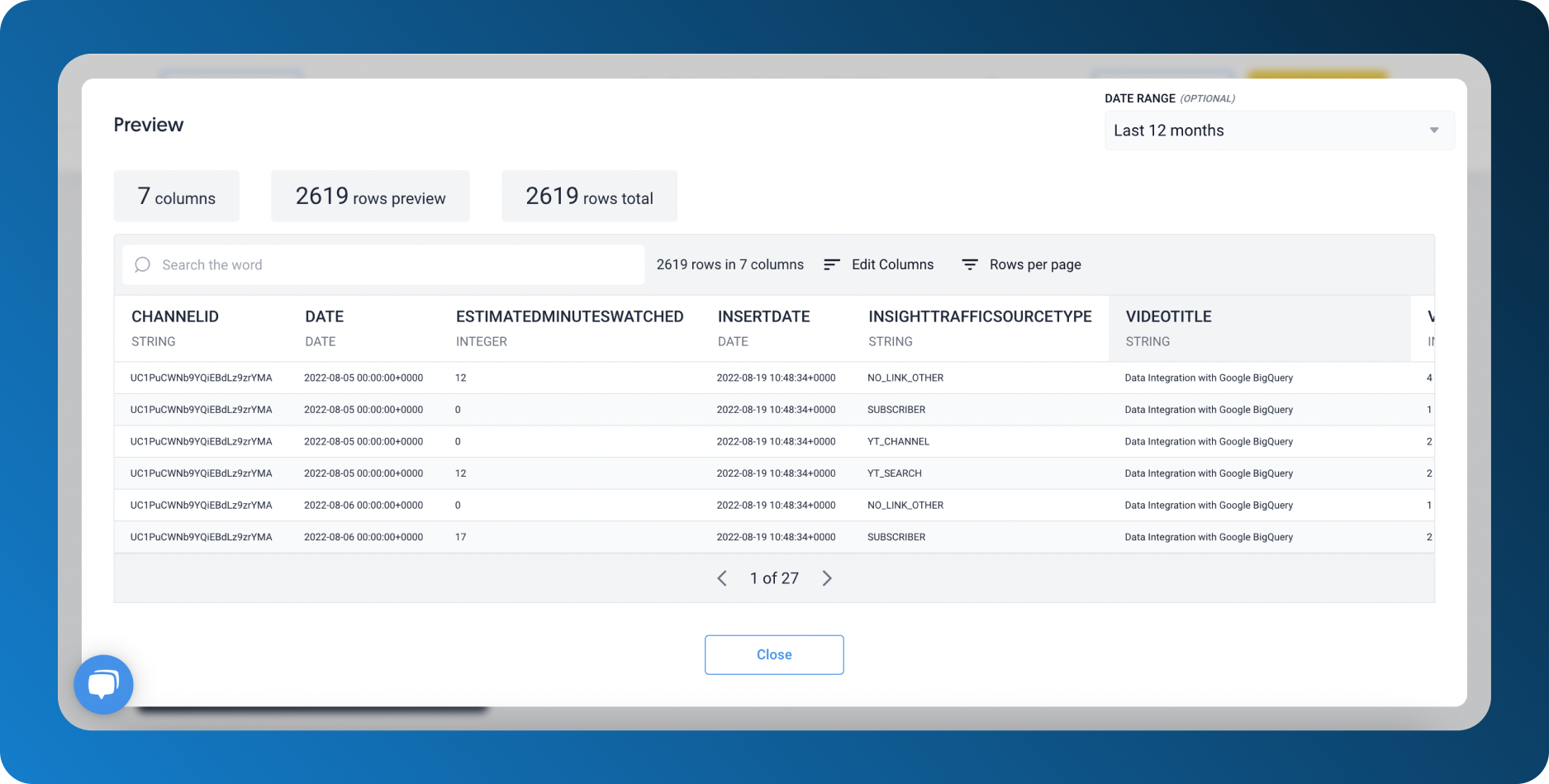
Set Up Your Destination
Under the Destinations tab click on Create a Destination and choose Universal MySQL.
Fill in the necessary information, and don’t forget to whitelist connections to your server from the following addresses:
52.17.68.150
52.30.37.137
52.214.115.147
Congratulations, your destination was set up! Let’s head to the last step.
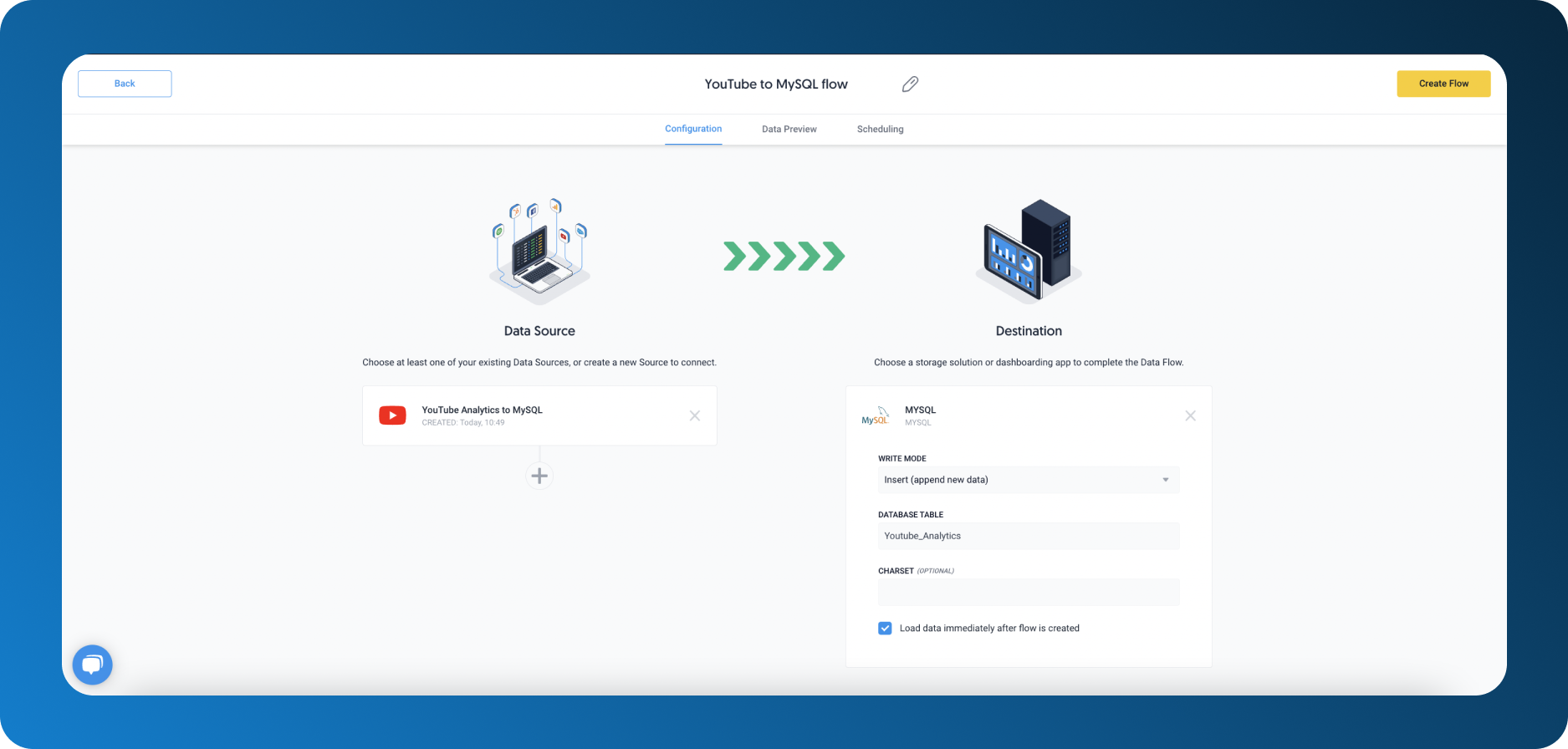
Create a Flow
Under your Flows tab, click on Create Flow. Add your source (or sources), destinations, and choose your write mode and voila! Your data pipeline has been successfully created.
The biggest advantage of ETL tools is that data pipeline maintenance is taken care of so you can focus on analyzing data. Connect even more sources in just a few clicks thanks to a standardized list of connectors. For example, Dataddo offers 200+ connectors and can build a new one free of charge.
The downside is that most ETL tools charge you per data volume. As a result, there may be unpleasant surprises when the bill comes. To avoid this, Dataddo charges you according to the number of your flows/sources, so that you always know beforehand how much you will pay.
Conclusion
From this article, it is quite clear that we strongly discourage you from the manual approach as it can be very unreliable despite being costly and time-consuming. Quite frankly, it hardly has any positives. Proceed with extreme caution and if possible, switch to automated data pipelines as fast as possible.
To choose between writing your own script and ETL tools, you need to take into account your business needs and priorities. It’s impossible to say which way is better and both have pros and cons.
Data extraction is a necessary step before you can proceed to data-driven decision-making. However, the time spent on the process does not contribute to the quality of your data analysis. This is why you should strive to choose the fastest, simplest, and least painful way to extract and load data to have more time for data insights themselves.
|
See how YouTube Analytics data can help your company. Just a few quick steps to get your data to your warehouse for better analysis, without the hassle.
|


Comments