

Google BigQuery is a robust cloud-based data warehousing solution that offers both ease of use and scalability. However, one potential reason why teams struggle with data quality in BigQuery is data duplication. It can occur for many reasons, including the initial design of BigQuery as an append-first database. It means that when data is ingested into BigQuery, it is stored in an append-only fashion. This architecture design can lead to duplicate records, as new records are added without first checking for duplicates.
Understanding the internals
Append-only by design
To understand the nature of common issues, such as duplicate data, when working with BigQuery, it is vital to dig deeper into the technology. One of the key features of Google BigQuery is its append-only approach to storing data. This generally means that once data is added to a table, it cannot be modified. While this may seem like a limiting factor, it actually provides several advantages.
First, it ensures that data is not accidentally overwritten. Second, it makes it easy to track changes over time and compare different versions of a dataset. Third, it simplifies data security by allowing administrators to set strict controls on who can access which data. Overall, the append-only approach offers numerous benefits for organizations that need to manage large amounts of data. Although Google engineers and architects are gradually shifting away from this approach, there are still some relics like the inability to run an UPDATE query on a row that will probably (and for a good reason!) last forever.
A victim of its success
Because Google BigQuery is a fast, scalable, and easy-to-use cloud data warehouse, it has quickly become a popular choice for many organizations, especially those utilizing other Google Cloud offerings. It is powered by Google's internal infrastructure and has no server or database administration required. You can spin up a BigQuery instance in minutes and start querying your data immediately. The pricing is also very attractive, with a cost of only $5 per TB of data processed, making it a much more affordable option than traditional relational SQL databases. As a result, BigQuery is often deployed in use cases that relational SQL databases would traditionally handle.
However, the original append-only design anticipates the "data lake" approach for working with the data - collect everything in the storage and deal with the processing and transformations later. This approach makes data insertion as easy as possible but on the other hand, relies heavily on robust data transformations for processing the data to be "analytics-ready". Given that many deployments of BigQuery are not the fit for its original design, this often results in issues that are often avoidable on the data architecture level, and one of the most prominent ones is preventing data duplication.
Start with reassessing your data architecture.
An excellent way to start is to reassess the data architecture. By carefully reviewing how data is stored and accessed, it is possible to identify, prevent and eliminate most of the issues, including duplicates. This can help improve query results' accuracy and free up storage space. In addition, reassessing the data and schema architecture can help to identify other areas where Google BigQuery can be used more efficiently.
- Identify each table that acts as a destination in the ETL process. For example, imagine extracting the data about Orders, Customers and Products from your e-commerce platform. In this case, you will have three tables - orders, customers and products.
- Identify how you want to store the data in each table. In general, there are three basic strategies that will be covered in the following paragraph.
Identify the right data storage strategy for each table
- Latest records only. This strategy is used when you need to have a 1:1 data replica of the source data in the table. I.e. data synchronization job replaces everything in the table with fresh data. For instance, the sync job gets the full list of customers from your e-commerce platform. There is no need to store the data from the previous jobs because you are only interested in the actual state of the data. The drawback is that this strategy might require quite heavy transformations, so your internal staff should have a good knowledge of standard SQL and as well of some more advanced concepts such as aggregations or window functions.
- Incrementally storing the data. This strategy is most in-line with the original BigQuery design. Basically, each sync job appends the data to the table and preserves the existing one. The great benefit of this strategy is in implicit creation of time series that allows you to track the changes in time. Given the situation, you want to use the strategy for synchronizing product data. With every sync job, you will get the 'snapshot in time' stored in the database. By utilizing this approach, you can, for instance, nicely track the price evolution of each product.
- Capture the changes only. This strategy should be used when for any reason it is not possible to extract the full data from the sources system. A common example of the limitations of the e-commerce platform API is that you cannot get the full list of orders, only the latest records, or only the recently changed records. This strategy allows you to preserve everything present in the table but, at the same time, update the rows that have changed.
Setting the correct write mode in the ETL process.
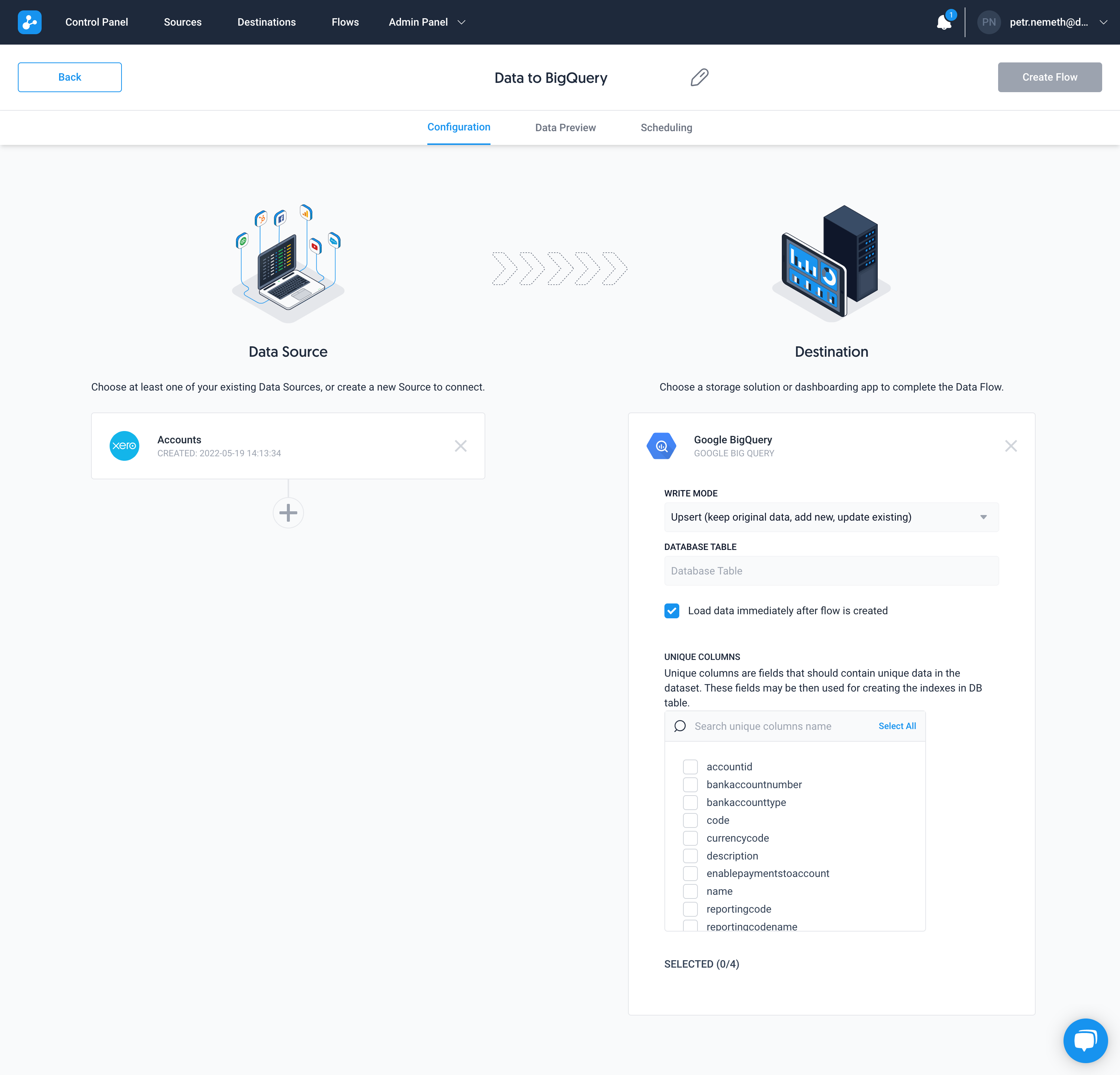
Dataddo offers multiple write modes to Google Big Query which when in line with the strategy can prevent duplicate data. The first write mode is 'Truncate insert' (replace the table). This will clear all data in the destination table and replace it with data from the source. The second write mode is 'Insert' (append to the table). This will append new records to the destination table, but will not overwrite any existing data. The third write mode is 'Upsert' (update table). This will update existing records in the destination table and insert the new data. Choosing the correct write mode is essential to preventing duplicate data in Google Big Query.
Need to store the entire data incrementally? Add a timestamp column to your Google BigQuery table.
Adding an extra timestamp column to the Google BigQuery table is a great and efficient way to deal with duplicities. This will help ensure that only unique data is inserted and duplicates are easily identified and removed. Moreover, you will end up having a complete log of changes. So, for instance, for each unique product identifier, you will have multiple rows capturing the changes in time. Dataddo platform provides a feature of adding the "Dataddo Extraction Timestamp" column during the ETL / ELT processes, so each row is automatically marked with the time of extraction.
Need keeping the latest records only? Use 'Truncate Insert' write mode.
When you only need to keep the data from the last data sync operation (e.g. the latest state of your customer table extracted from an e-commerce platform), use the "Truncate Insert" mode in Dataddo. This mode erases all the data in the existing table before inserting it into the big query. It would be best if you were using this mode only when you do not need to preserve incremental changes of the data and are interested only in capturing the actual "snapshot".
Need to update the changed rows only and keep the rest? Use 'Upsert' write mode.
Dataddo's UPSERT mode automatically detects which rows need to be updated and which will be inserted utilizing the MERGE table algorithm. With the MERGE table algorithm, Dataddo first attempts to match each incoming row to an existing row in the destination table using a user-specified key column. If a matching row is found, Dataddo updates the destination table with the values from the incoming row. If a matching row is not found, Dataddo inserts a new row in the destination table with the values from the incoming row. This MERGE table algorithm can be used to keep two datasets synchronized without having to perform a full replacement each time.

Comments