

Data quality is and always has been a problem for just about every type of organization. Governments, militaries, healthcare providers, businesses—all must strive not only to keep data accurate, but to ensure that it is shared with the right people at the right time.
Failures to do so have led to consequences as minor as incorrect birth dates on medical cards, and as major as the bombing of the US Pacific Fleet at Pearl Harbor during WWII.
%201.png?width=1200&name=1200px-Pearl_harbour%20(1)%201.png) Lack of American preparedness for the attack was due to inadequate sharing of information between government agencies.
Lack of American preparedness for the attack was due to inadequate sharing of information between government agencies.
Fortunately for businesses, the stakes are not as high as for militaries or healthcare providers. But the point remains: good quality data is key to successful operations.
Every business should be asking questions like:
- How much is poor-quality data costing us?
- Are our teams struggling with data quality issues?
- How can we ensure that data is both accurate and interpreted correctly?
- How will master data be stored and distributed throughout our organization?
- What rights and accountabilities should be granted to whom?
The answers to these questions are compound and involve a range of organizational and technological solutions.
Organizational solutions for data quality have been around since humans have been collecting data.
But technological solutions are just now becoming widespread, with Gartner stating that “By 2022, 60% of organizations will leverage augmented data quality solutions to reduce manual tasks for data quality improvements.”
This article will examine both types of solutions and leave you with an understanding of what next steps you can take to improve data quality within your company.
Organizational Solutions for Quality Data
Organizational solutions for data quality management are primarily procedural and people-focused. This means they revolve around policies, methods, and overall development of company culture.
It also means that they are formulated according to the needs, industry, size, etc. of each individual business.
It's therefore hard to narrow them down into a one-size-fits-all checklist. But for most businesses, organizational solutions fall into two general categories: those that concern company culture and those that concern data governance.
Make Data an Integral Part of Company Culture
One of the greatest barriers to proper data management within companies is culture. Executives don't want to buy in on data initiatives and employees don't feel confident in their data literacy skills.
When we think of data, we think about artificial intelligence and high-tech tools. But, again according to Gartner, "the real divers of [data-driven culture] are the people."
Cultural solutions should come from the top and include things like:
- Hiring a Chief Data Officer
- Investing in data literacy training
- Appointing a citizen data scientist to each department
Citizen Data Scientists
Citizen data scientists (also called data stewards) are people who have some data expertise, but whose core competencies are more aligned with their respective non-data departments (marketing, sales, HR, etc.).
Data stewards bridge the gap between data and business teams, and help increase the data literacy of employees around them. This can lead to increased confidence in data initiatives, better decision-making, and better ability to spot errors and inconsistencies. Their duties could include:
Next Step
Making data an integral part of company culture doesn't have to involve major costs or complicated tools. On the contrary, it can start with something as simple as tracking a few key metrics in spreadsheets.
Sign up for a free trial of Dataddo and easily automate the flow of data from any cloud service to any Google Sheet. No coding is necessary, so it can help anyone get used to interpreting data.
Initiate a Companywide Data Governance Policy
Simply defined, a data governance policy is the rules and procedures by which data is managed within a business. It has two main aims:
- Ensure that all departments are working with the same understanding of what data is, how it should be used, and who has access to it.
- Give all employees a clear set of guidelines to follow when working with data.
Governance policies are essential for data quality management. Indeed, a recent survey by Dataversity of business technology professionals found that over half of organizations already have a formal policy in place. And the main driver behind such policies is more confidence in decision-making. The incentive to initiate one is therefore clear.
Policies not only seek to ensure data quality and accuracy, but also cover security and permissions. They often provide:
- Definitions of different types of data
- Key metrics
- Procedures for investigating inaccuracies and inconsistent data
- Security protocols
By and large, traditional models of data governance—in which data is almost entirely centralized—are no longer sustainable because line-of-business professionals need more flexibility in analytics for quicker insights. This is why we are currently witnessing a trend toward decentralization and self-service analytics.
But neither extreme centralization nor extreme decentralization is practical. Any organization today will want to find some balance between the two. More centralization gives more control over data security and quality, but less data usability; more decentralization gives the opposite.
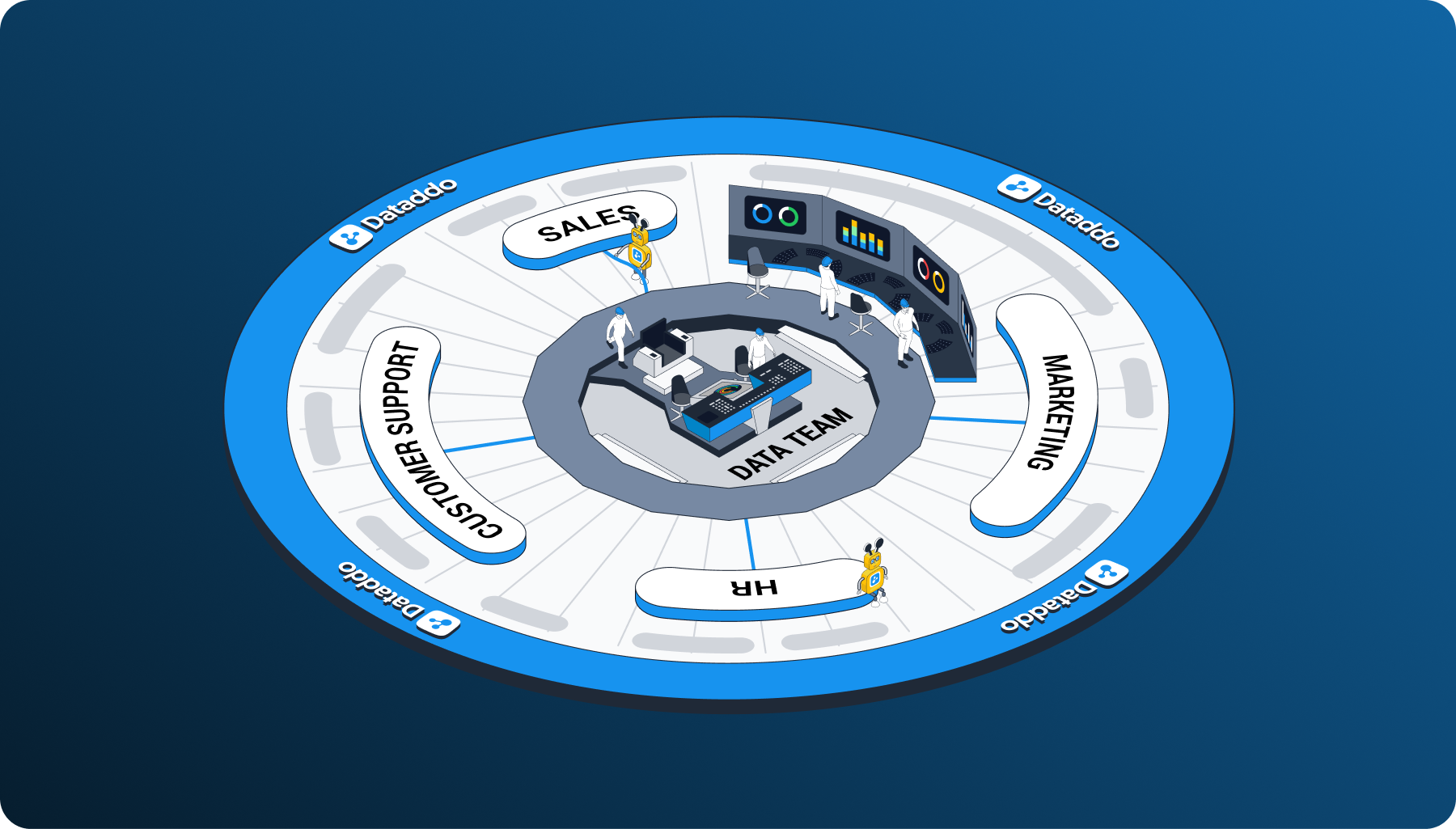 A visual representation of how the hub and spoke model of data governance might be implemented.
A visual representation of how the hub and spoke model of data governance might be implemented.
One governance model that gives businesses the best of both worlds is the hub and spoke model.
Next Step
An easy step toward formulating a working governance policy is to define key metrics and set permission levels and access rights. Then, as time goes on, inaccuracies will emerge, at which point error investigation procedures can be determined, source systems can be reconfigured by data teams, and so on.
Technological Solutions for Quality Data
With data coming from an increasing number of systems and being manipulated by an increasing number of non-technical professionals, technological solutions for high-quality data will become an ever-more important supplement to the organizational solutions mentioned above.
Among other things, they serve to:
- Equip business professionals with engineering capabilities
- Help establish a consistent, single source of truth
- Facilitate the processing of AI workloads
- Filter out poor quality data from datasets
Unlike organizational solutions, which are policies and procedures, technological solutions for data quality management are specialized tools.
No-Code Data Integration Tools
No-code data integration tools play a big role in improving data quality, especially for non-technical users. This is for a couple of reasons.
#1 - They Produce Analytics-Ready Data
Unlike traditional data integration tools, which can only send data to warehouses, they can send data directly to dashboards in analytics-ready form.
What makes it analytics-ready is the transformations that automatically take place under the hood of such tools. These harmonize structures and formats (e.g. dates) so that data from different tools can be put side by side into the same table. They also make it machine-readable, which is essential for AI workloads.

Advanced transformations and data cleansing are still often performed by engineers in downstream systems, but the fact that data can now be sent directly to dashboarding apps is a huge step towards decentralized data management. Moreover, if data extracted by an integration tool is funneled to downstream systems, it will be easier for engineers to work with since it's already pre-transformed.
No-code data integration tools are one of the best ways to keep data clean, straight out of the chute.
#2 - They Allow Data Flows to Be Automated. By Anyone.
First of all, this is crucial for consistency. If everyone is automatically served the same, up-to-date, consistent data on their dashboard every morning, everyone will literally be on the same page.
Second of all, since they can be used by anyone, they support users with any level of data access. In organizations with stricter governance policies, like banks, they can be used by engineers to send data to view-only dashboards for business professionals. In organizations with more relaxed governance policies, like ecommerce startups, business professionals can use them to build pipelines themselves.
This essentially means that they are capable of giving any professional, regardless of permissions, access to the data they need to make informed decisions.
For cases where business teams have the required permissions and technical know-how, they also allow engineers to replicate data from main storages to secondary storages. This gives each business team its own data sandbox.
In a nutshell, this capability enables data to be shared consistently, without compromising security or the quality of a company's master data.
#3 - They Are Fully Managed
Every cloud service has what's called an application programming interface (API), which—among other things—is what allows it to connect with other external tools.
For a million reasons, the APIs of these services are always changing. Every time they do, the connection with other external tools breaks. These connections (or integrations) therefore have to be constantly maintenanced by engineers. And in companies that don't have a whole team dedicated to maintenance, fixing these breaks can take a while and therefore lead to data loss.
Sometimes pipelines break for other reasons as well (improper source configurations, unauthorized changes, hardware and network hiccups, etc.).
But since no-code data integration tools are fully managed, there is a full team of engineers that proactively adapts integrations to API changes, and monitors and fixes broken pipelines, minimizing downtime and the possibility of data loss.
#Bonus
Dataddo, a no-code data integration tool, features a built-in anomaly detection engine, automatic data quality assessment reports, and a robust notification system.
Dataddo uses rule-based integration triggers to keep questionable datasets out of your warehouse and dashboards. Simply set a threshold for null values or anomalies, and if the threshold is exceeded, the integration will not trigger.
Any data you extract is also subject to automatic data quality checks. Our quality reports show you any null values, zero values, and anomalies per row.
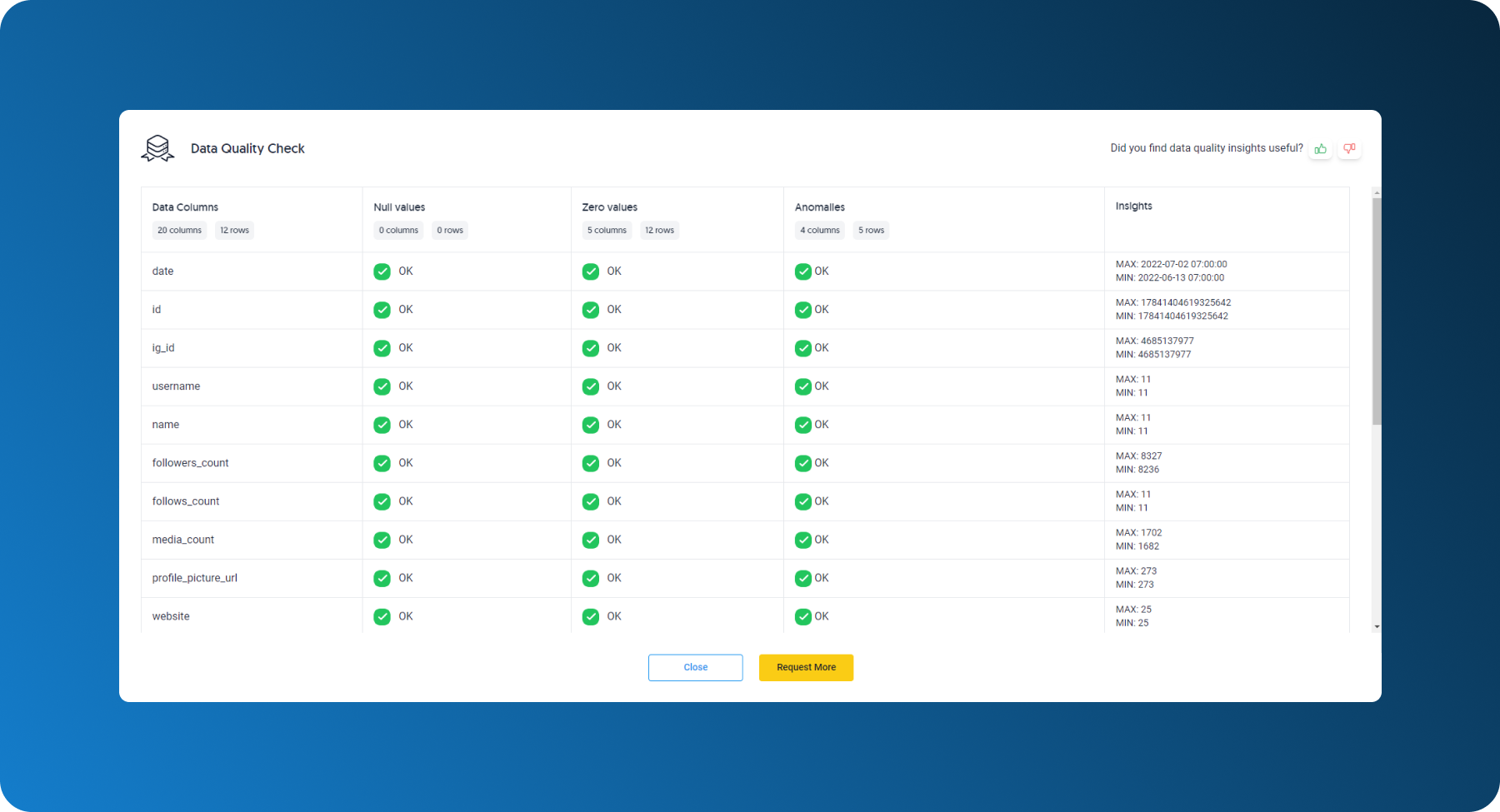
Finally, when using Dataddo, you'll receive automatic notifications in case of broken sources and flows, as well as personal notifications from our team in case we need your help fixing them.
Next Step
See our comprehensive list of data integration tools for more information and guidance on what data integration tool might be right for your use case (note: not all of these are no-code).
Cloud Data Warehouses
A data warehouse is essential for master data management. It is key to establishing a single source of truth, which in turn is key to maintaining good data quality. And in this day and age, it's important to pick a cloud data warehouse. This is because they are fully managed, highly scalable, and generally cheaper than on-premise solutions. Plus, keeping data in the cloud is a good way to protect against acts of God (you never know what might happen).
When striving for high-quality data, there are 2 main benefits of having a data warehouse:
#1 - Storing Historical Data
Having a data warehouse is the only practical way to store all your data, as far back in time as you like.
Cloud services only store data for limited periods of time. Google Analytics 4, for example, only stores data for a maximum of 14 months.
Not only can data warehouses store data indefinitely, they have virtually no storage limits. This is crucial for things like marketing attribution, which requires the use of historical data.
These capabilities make cloud data warehouses the ideal single source of truth—the data inside them will always be there to verify the accuracy of any other data.

#2 - Data Cleansing
Data warehouses are the operating table for advanced transformations and cleansing.
Even though no-code data integration tools perform essential data cleansing thanks to automatic transformations, it is often the case that data needs to be cleansed and transformed further by engineers for more advanced insights.
Types of transformations/cleansing operations include:
- Grouping similar data types
- Computations and aggregations
- Eliminating duplicated data (very common with ecommerce data, as many records are re-entered during checkout)
- Blending datasets for advanced insights
Data that is transformed is higher in quality, contains fewer errors, can be queried faster, and provides the most advanced business intelligence.
Next Step
See our blog on cloud data warehouse solutions for more information on what to consider when choosing a data warehouse, as well as a list of warehouses and their pros and cons.
Filtering Tools
Filtering tools exclude certain types of data from entering endpoint systems like data warehouses and dashboards. These could be duplicate data, outliers and anomalies, incorrect data types, and invalid traffic.
One notable type of filtering tool is AI-based anomaly detectors. Recently, there has been a surge in the development of such tools, which are able to automatically learn the normal behavior of a system and then flag up potential anomalies.
Another notable type of filtering tool is invalid web traffic filters. Invalid web traffic (IVT) accounts for nearly half of all web traffic today (e.g bots), which is a big problem for marketers in particular. Imagine running an ad campaign that gets an extremely high click-through rate thanks to IVT. Not knowing that the results are false, you might repeat your strategy and continue advertising to nobody. For such cases, IVT filters are an important component of good quality data.
Data integration tools also offer a number of manual filtering options, letting you pick and choose the datasets you send to your warehouse or dashboard. This is highly useful for keeping data organized, because cloud-based services are generally only capable of an “all or nothing” data dump, causing a mess in data warehouses and timed-out connections when they are linked directly to dashboarding apps.
Next Steps
- See this list of dedicated anomaly detectors
- Try a full iteration of the Dataddo platform for free and play with manual data filtering
No Cure-All Solution for Data Quality Management
The key difference between organizational and technological solutions for high-quality data is that organizational solutions are policies, procedures, and methods, while technological solutions are specialized data quality tools.
Technological solutions are getting better as you read this, but they will always be a supplement to—and never a replacement for—organizational solutions.
Data quality can never be perfect all of the time. But it can be good most of the time when supported by a combination of both solution types. This means:
- Fostering a culture of data within your company
- Gradually implementing a comprehensive data governance policy
- Using no-code data integration tools that give an essential standard of quality to any extracted dataset
- Establishing a data warehouse as your single source of truth
- Using filtering tools to keep data clean
With data becoming a core function of business operations across industries, companies will need to adopt and adapt various combinations of solutions as their use case evolves.
Good data quality is not a final destination. It's an ongoing journey.
|
No-Code Data Integration Tools Improve Data Quality Try Dataddo today and send analytics-ready data from any source to any destination in minutes.
|


Comments