

Data governance is a critical practice for unlocking the true potential of data. By implementing robust data governance practices, organizations can transform data into a strategic asset that fuels informed decision-making and drives success.
Let’s explore the connection between data quality and governance, as well as how to keep data high-quality throughout its lifecycle.
Click to skip down to a specific section:
- Connection between data quality and data governance
- Common data quality challenges
- Key characteristics of high-quality data
- Steps to ensure effective data governance for improved data quality
- Hub-and-spoke model of data governance
Connection Between Data Quality and Governance
Data governance establishes the foundation for achieving and maintaining data quality. It sets the rules, processes, and roles that ensure data is managed effectively throughout its journey—from initial collection to final analysis.
During collection and ingestion, data from different sources needs to be standardized and properly mapped to tables in the target database.
During preparation and storage, data needs to be further transformed, profiled, and double-checked for quality.
During visualization and use, data needs to be interpreted according to standard definitions, by authorized users, and cross-checked in various visualization tools.
During all these phases, data needs to be monitored and tracked.
Here is an example of a data governance framework designed to promote data quality across the data stack:
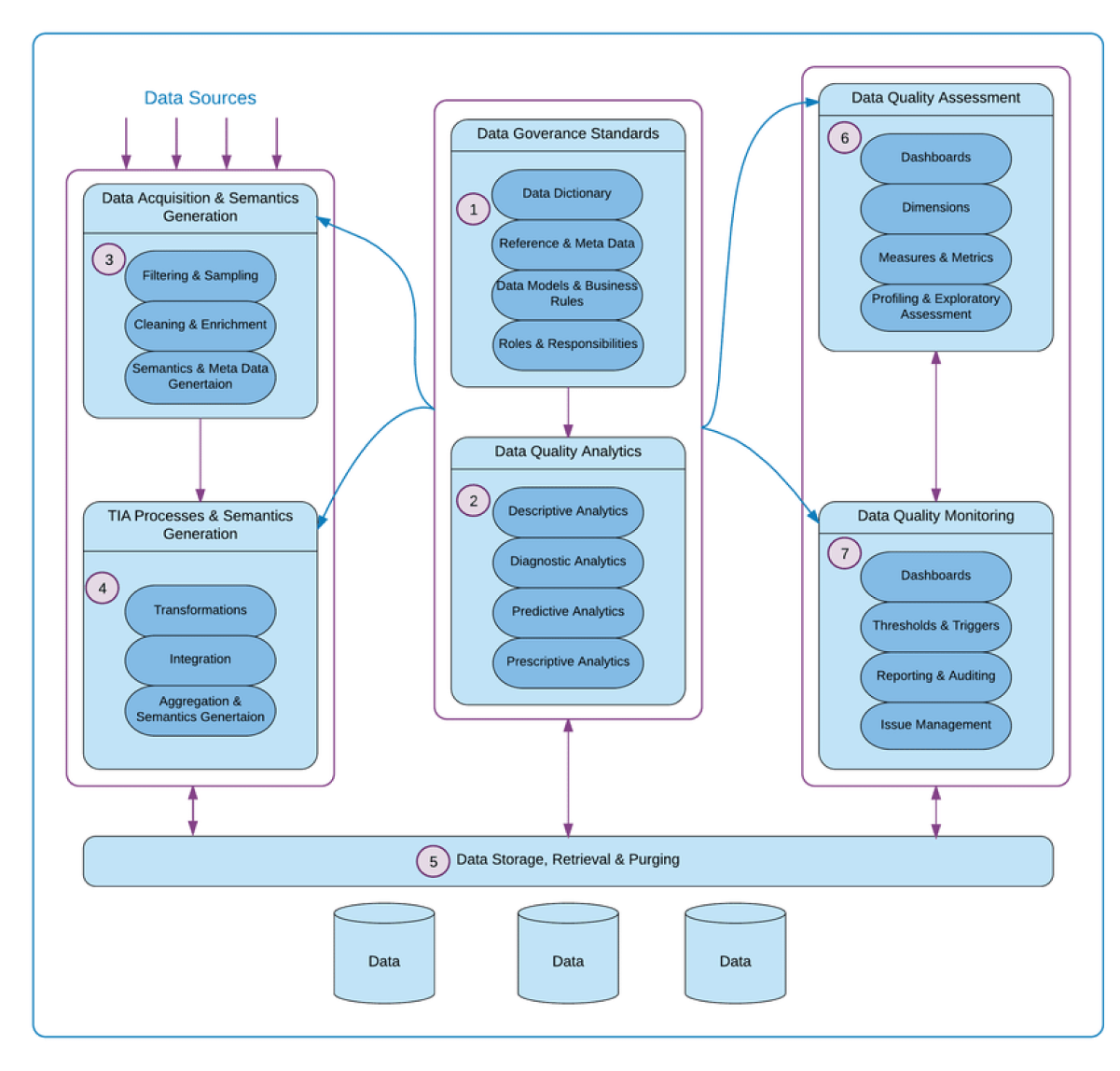
Common Data Quality Challenges
Despite the importance of data quality, maintaining it throughout the data lifecycle presents a challenge for many data and business teams. Here are some of the most common:
1. Data Silos & Fragmentation
When data is scattered across different systems and departments (data silos), it becomes difficult to ensure consistency and completeness. This fragmentation can lead to conflicting versions of the truth and hinder data analysis efforts.
2. Lack of Standardized Processes
The absence of clear standards for data collection, entry, and storage can create inconsistencies and errors. Without established procedures, data becomes subjective and prone to human bias.
3. Human Error
Even with the best intentions, human error during data entry or manipulation can lead to inaccuracies. Typos, misinterpretations, and accidental data deletion can significantly impact data quality.
4. Technological Limitations
Outdated data management systems might be unable to handle complex data formats or enforce data quality rules. Additionally, limitations in data integration tools can create inconsistencies when merging data from various sources.

Poor data quality can have a significant negative impact on business operations, in the form of wasted resources, inaccurate reporting, flawed decision-making, and even compliance risks.
Key Characteristics of High-Quality Data
Various characteristics comprise the overall trustworthiness of any dataset. Let's explore seven:
- Validity: Data must adhere to defined formats and standards. Imagine an address field that only accepts numerical values for zip codes; this would prevent the entry of invalid data that could skew analysis.
- Accuracy: Data must accurately reflect the real-world value it represents; inaccurate data can lead to false insights and poor decision-making. For example, inaccurate stock prices within a financial data feed could lead investors to make poor investment decisions.
- Completeness: A complete dataset must contain all the necessary data points required for analysis. Incomplete data, like missing contact information or blank fields, can hinder the ability to draw meaningful insights.
- Consistency: Consistency ensures that data adheres to the same definitions and formats across an entire system. For example, a customer's name should be formatted similarly (e.g., Last Name, First Name) across all databases. Inconsistencies can create confusion and complicate data analysis.
- Uniqueness: No duplicate records should exist within a dataset, as they can inflate data volumes and skew results. Ensuring each customer record has a unique identifier prevents duplicate entries, leading to accurate customer insights and targeted marketing campaigns. In case the only identifier is sensitive information like an email address, then it should be hashed for better security.
- Timeliness: Data should be up-to-date and reflect recent information. Imagine relying on outdated inventory levels to make production decisions—that's the risk of untimely data. Timeliness is one major benefit of using an automated data integration tool to sync data at regular intervals.
- Relevance: Irrelevant data adds unnecessary complexity and reduces the effectiveness of data-driven activities. Data relevance ensures the information pertains to the specific use case or analysis at hand. For example, targeting the right customer segment in a marketing campaign (high relevance) avoids wasted ad spending on irrelevant audiences.
Steps to Ensure Effective Data Governance for Improved Data Quality
Data governance provides a strategic framework for tackling data quality challenges and creating a foundation for trusted information. Here are some key steps to ensure effective data governance.
-
Establish Clear Data Governance Policies
The lack of clear guidelines leads to inconsistent data practices across departments.
Develop a comprehensive set of policies defining data management roles and responsibilities. These policies should outline data quality standards, access controls, and procedures for data collection, storage, and usage. Clear policies ensure that data is consistent and managed in the same way throughout the organization, leading to increased compliance, transparency, security, and quality of data.
For instance, a healthcare provider can implement a data governance policy defining a standardized format for patient records (e.g., date of birth) across all departments to ensure consistent data for billing and treatment purposes.
This is especially important for enterprise data integration.
2. Define Data Ownership & Accountability
Unclear ownership leads to fragmented data management and potential neglect.
Assign clear ownership of specific data sets within the organization. Data owners are responsible for ensuring the accuracy, completeness, and timeliness of their assigned data. This fosters accountability and promotes a sense of responsibility for data quality.
For example, you could assign ownership of customer email data to someone in the marketing team, in order to ensure its accuracy for email marketing campaigns.
3. Standardization
Inconsistent data formats and definitions across systems lead to integration issues and inaccurate analysis.
Therefore, implement standardized data formats, definitions, and naming conventions throughout your organization. Standardize data entry procedures and establish clear guidelines for data cleansing and correction. This reduces inconsistencies and simplifies data integration and analysis.
A retail company, for example, can standardize product descriptions across its ecommerce platform and physical stores to improve data integration and customer search experiences.
Automated ETL tools like Dataddo are a major assistance when it comes to standardization, because they unify the formats of data they extract from disparate sources.
4. Data Quality Measurements
Without quality measurement, it can be difficult to identify and address data quality issues.
Define key performance indicators (KPIs) to monitor the health of your data. These metrics might include error rates, missing data percentages, and duplicate record counts. Regularly track these KPIs to identify areas for improvement and measure the effectiveness of data governance initiatives.
A manufacturing company, for instance, can track the percentage of missing zip codes in customer shipping addresses. Regularly tracking these KPIs enables swift identification and resolution of data quality issues.
5. Data Profiling and Cleansing
Dirty data (e.g., duplicates, invalid entries) can have a significant negative impact on analysis.
So, regularly profile your data. Data profiling helps uncover inconsistencies, missing values, and duplicate records. Implement data cleansing processes to correct errors, fill in missing information, and eliminate duplicates for data accuracy and completeness.
When possible, use automated ETL tools like Dataddo, which automatically pre-cleanse data, and whose write modes help eliminate duplicates. Dataddo’s Data Quality Firewall also blocks anomalous data from entering storages, significantly reducing the cost of data cleansing in data warehouses.
6. Data Quality Tools
Data quality tools and processes automate many aspects of data governance, streamlining tasks and improving efficiency. These tools are for workloads like data integration, data profiling, data cleansing, data validation tools, and data monitoring solutions.
By leveraging these tools, organizations can automate error detection and correction, identify data inconsistencies proactively, and enforce data quality standards throughout the data lifecycle. This significantly reduces human error and streamlines achieving all characteristics of high-quality data.
7. Data Lineage and Auditing
Difficulty tracing the origin and movement of data creates uncertainty about its reliability.
Implement data lineage tracking to understand the origin and transformation of data throughout its lifecycle for its accuracy and trustworthiness.
This allows you to identify the source of any errors and trace their impact on downstream analyses. Moreover, data auditing procedures must be established to monitor data access and usage, ensuring compliance with regulations and security protocols.
In the insurance sector, for example, implementing data lineage tracking can facilitate understanding of policyholder data origins and ensure compliance with regulatory requirements.
The Hub and Spoke Model of Data Governance
One increasingly popular model for implementing data governance is the hub & spoke model.
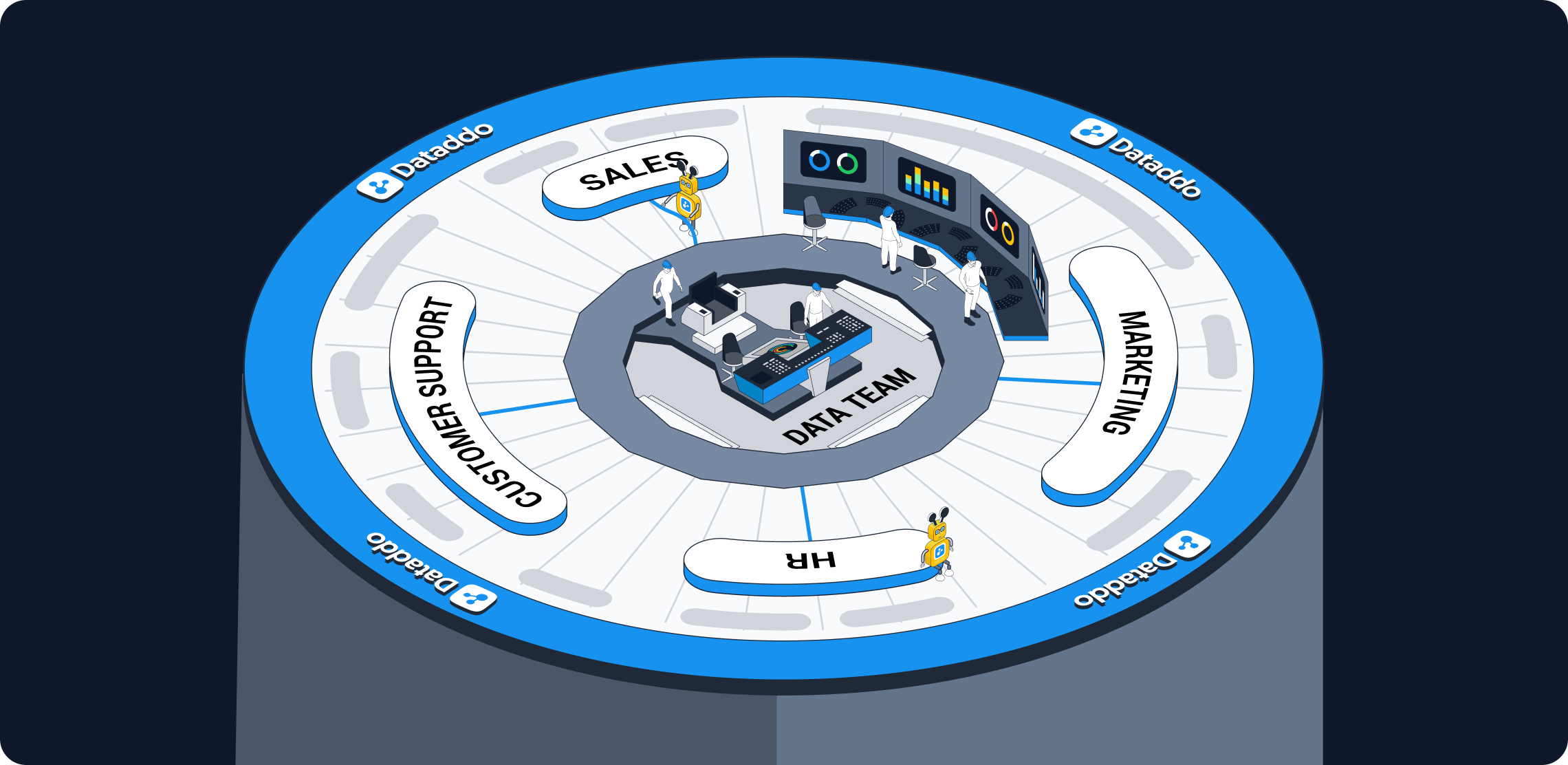
In the hub and spoke model, data teams (the hub) remain in control of data quality and storage, as they always have, but end users (the spokes) have more power to manipulate data, to the maximum extent possible within any governance policy. This puts the analytics competencies with the teams that actually need insights, and frees data teams to focus on their core mission: ensuring quality and security.
In a hub-and-spoke governance model, Dataddo can support both the hub and the spokes. Business units can leverage our no-code interface to send data from online services to BI tools, and data teams can get under the hood of our app to program heavy integration workloads via code.
For more on the hub and spoke model of data governance, read this article by Dataddo CEO Petr Nemeth.
Data Quality Is a Process, Not a State
Data quality issues will never cease to occur, so foster a culture of continuous improvement within your organization by encouraging feedback and suggestions from data users. Regularly review and update your data governance policies and procedures to adapt to evolving data needs and technologies, as well as regulatory requirements.
By following the steps above, organizations can establish effective data governance frameworks that promote data quality, integrity, and—ultimately—decision-making throughout the data lifecycle.
|
Connect All Your Data with Dataddo ETL, ELT, reverse ETL. Full suite of data quality features. Maintenance-free. Coding-optional interface. SOC 2 Type II certified. Predictable pricing.
|


Comments