

When it comes to data, sharing is not always caring.
Yes, the increased flow of data across departments like marketing, sales, and HR is doing much to power better decision-making, enhance customer experience, and—ultimately—improve business outcomes. But this has serious implications for security and compliance.
This article will discuss why, and then present three core principles for secure integration of data.
Click to skip straight to the principles:
- Separate concerns
- Use data exclusion and data masking techniques
- Keep a strong system of auditing and logging in place
Democratizing Access to Data: An Important Caveat
On the market today is an incredible range of no- and low-code tools for moving, sharing, and analyzing data. Extract, transform, load (ETL) and extract, load, transform (ELT) platforms, iPaaS platforms, data visualization apps, databases as a service—all of these can be used relatively easily by non-technical professionals and with minimal oversight from administrators.
Moreover, the number of SaaS apps that businesses use today is constantly growing, so the need for self-serve integrations will likely only increase.
Many such apps, like CRMs and EPRs, contain sensitive customer data, payroll data, invoicing data, and so on. These tend to have strictly controlled access levels, so, as long as the data stays inside them, there isn’t much of a security risk.
But, once you take data out of these environments and feed it to downstream systems with completely different access level controls, there emerges what we can term “access control misalignment.”
People working with ERP data in a warehouse, for example, may not have the same level of confidence from company management as the original ERP operators. So, by simply connecting an app to a data warehouse—something that’s more and more often becoming necessary—you run the risk of leaking sensitive data.
This can result in violation of regulations like GDPR for Europe or HIPAA for the US, as well as requirements for data security certifications like SOC 2 Type II, not to mention stakeholder trust.
3 Principles for Secure Data Integration
How to prevent the unnecessary flow of sensitive data to downstream systems? How to keep it secure in case it does need to be shared? And in case of a potential security incident, how to ensure that any damage is mitigated?
These questions will be addressed by the three principles below.
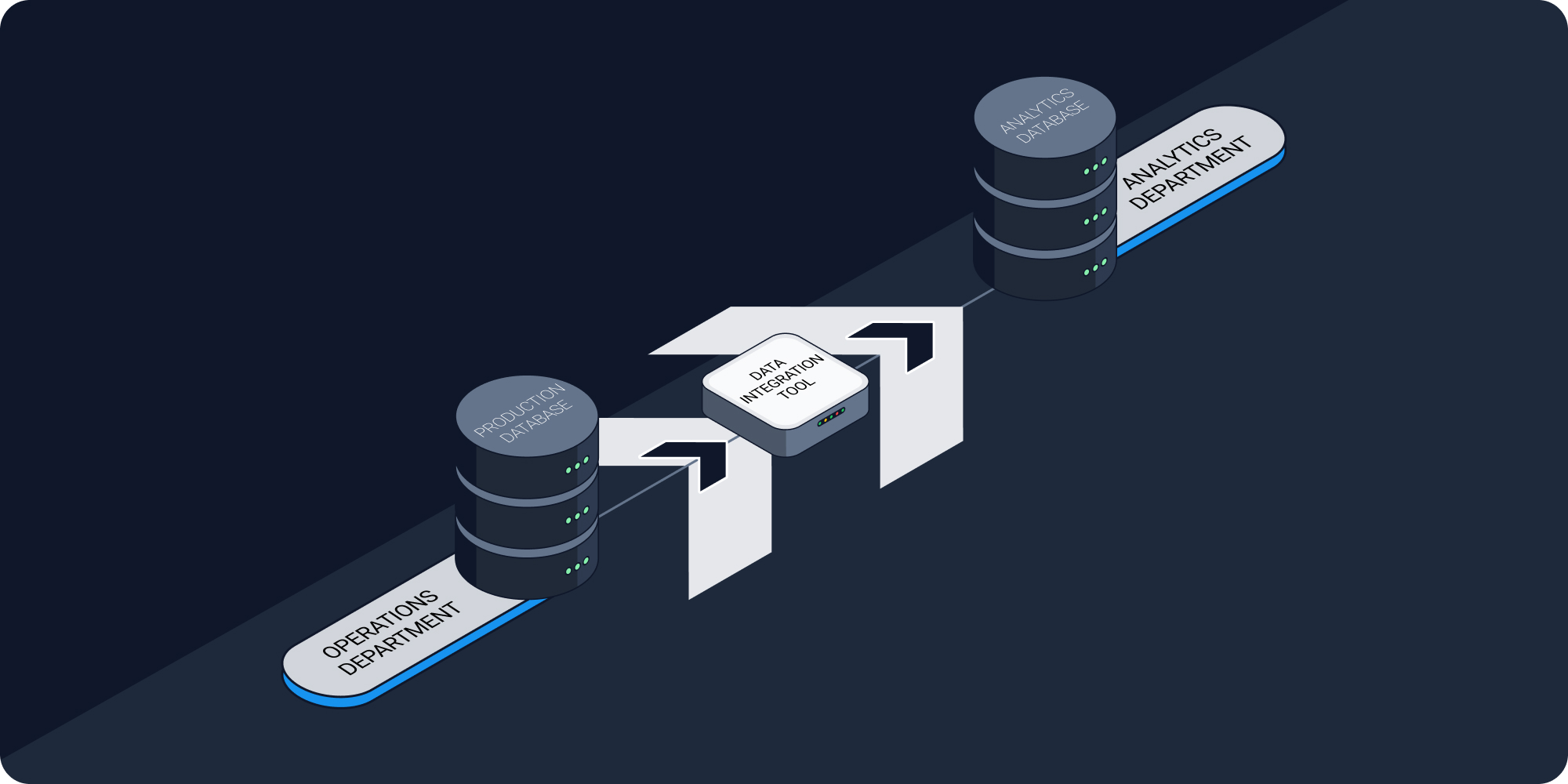
Separate Concerns
By separating data storage, processing, and visualization functions, businesses can minimize the risk of data breaches. Let’s illustrate how this works by example.
Imagine that you are an ecommerce company. Your main production database, which is connected to your CRM, payment gateway, and other apps, stores all your inventory, customer, and order info. As your company grows, you decide it’s time to hire your first data scientist. Naturally, the first thing they do is ask for access to datasets with all the abovementioned information, so that they can write data models for, let’s say, how the weather impacts the ordering process, or what the most popular item in a specific category is.
But, it’s not very practical to give the data scientist direct access to your main database. Even if they have the best of intentions, they may, for example, export sensitive customer data from that database to a dashboard that’s viewable by unauthorized users. Additionally, running analytics queries on a production database can slow it down to the point of inoperability.
The solution to this problem is to clearly define what kind of data needs to be analyzed and, by using various data replication techniques, to copy this data into a secondary warehouse designed specifically for analytics workloads, like Redshift, BigQuery, or Snowflake.
In this way, you prevent sensitive data from flowing downstream to the data scientist, and at the same time give them a secure sandbox environment that’s completely separate from your production database.
Use Data Exclusion and Data Masking Techniques
These two processes also help separate concerns because they prevent the flow of sensitive information to downstream systems entirely.
In fact, most data security and compliance issues can actually be solved right when the data is being extracted data from apps. After all, if there is no good reason to send customer telephone numbers from your CRM to your production database, why do it?
The idea of data exclusion is simple: If you have a system in place that allows you to select subsets of data for extraction, like an ETL tool, then you can simply not select the subsets that contain sensitive data.
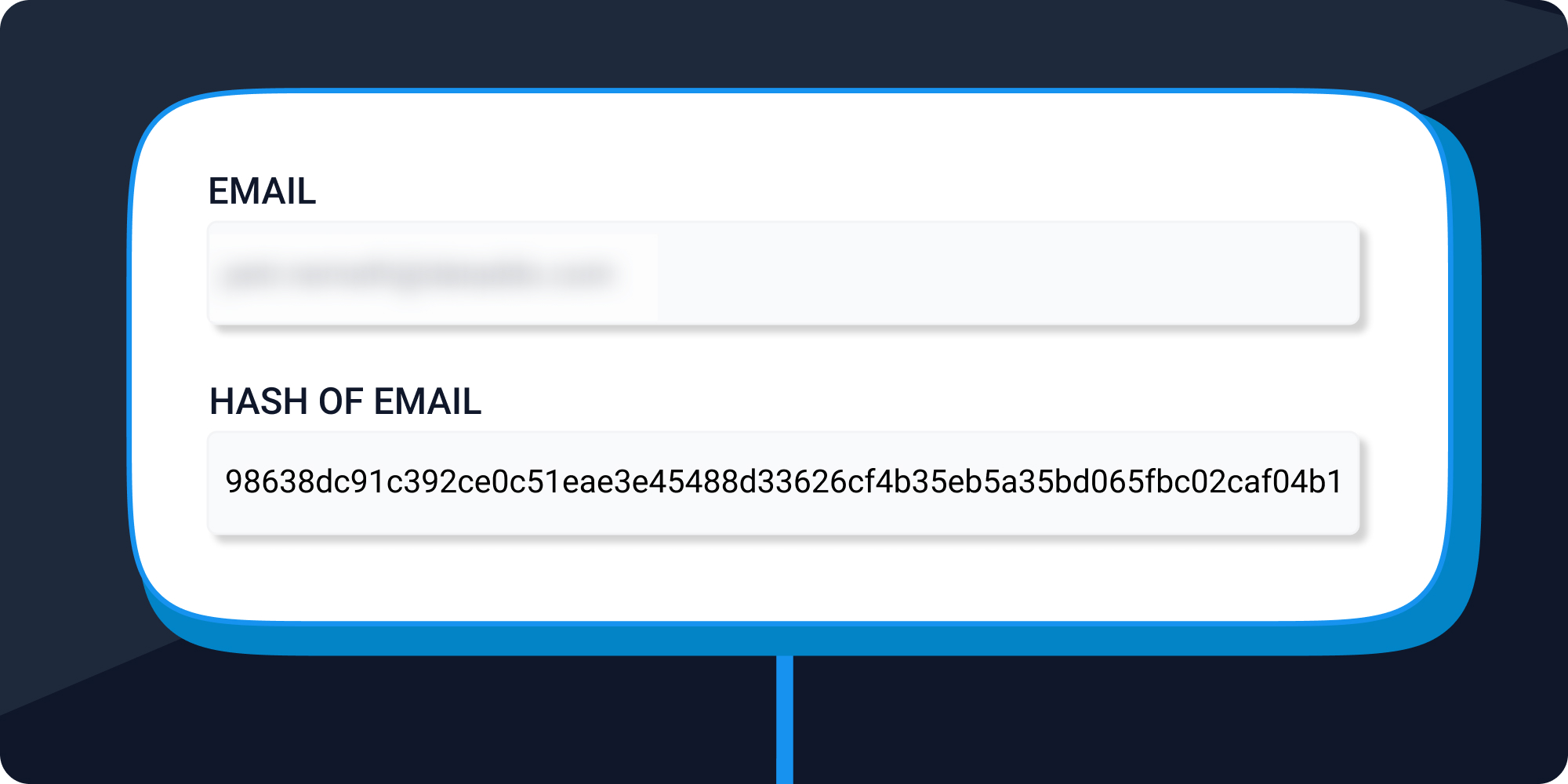
But, of course, there are some situations when sensitive data needs to be extracted and shared. This is where data masking/hashing comes in.
Let’s say, for instance, that you want to calculate health scores for customers and the only sensible identifier is their email address. This would require you to extract this information from your CRM to your downstream systems. To keep it secure from end to end, you can mask or hash it upon extraction. This preserves the uniqueness of the information, but makes the sensitive information itself unreadable.
Both data exclusion and data masking/hashing can be achieved with an ETL tool.
As a side note, it’s worth mentioning that ETL tools are generally considered more secure than extract, load, transform (ELT) tools because they allow data to be masked or hashed before it is loaded into the target system. For more information, see a detailed comparison of ETL and ELT tools.
Keep a Strong System of Auditing and Logging in Place
Lastly, as part of a comprehensive data governance policy, make sure there are systems in place that enable you to understand who is accessing data, how, and where the data is flowing.
Of course, this is important for compliance, because many regulations require organizations to demonstrate that they are tracking access to sensitive data. But it’s also essential for quickly detecting and reacting to any suspicious behavior.
Auditing and logging are both the internal responsibility of companies themselves, and the responsibility of the vendors of data tools, like pipelining solutions, data warehouses, and analytics platforms.
So, when evaluating such tools for inclusion in your data stack, it’s important to pay attention to whether they have sound logging capabilities, role-based access controls, and other security mechanisms like multi-factor authentications. SOC 2 Type II certification is also a good thing to look for, because it’s the standard for how digital companies should handle customer data.
This way, if a potential security incident ever does occur, you will be able to conduct a forensic analysis and mitigate the damage.
Access vs. Security: Not a Zero-Sum Game
As time goes on, businesses will increasingly be confronted with the need to share data, as well as the need to keep it secure. Fortunately, meeting one of these needs doesn’t have to mean neglecting the other.
The three principles outlined above can underlie a secure data integration strategy in organizations of any size.
First, identify what data can be shared, and then copy it into a secure sandbox environment.
Second, whenever possible, keep sensitive datasets in source systems by excluding them from pipelines, and be sure to hash or mask any sensitive data that does need to be extracted.
Third, make sure that your business itself and the tools in your data stack have strong systems of logging in place, so that if anything goes wrong, you can minimize damage and investigate properly.
*This article was originally published at Venturebeat.com.
|
Connect All Your Data with Dataddo Easily, securely, and reliably send data from any source to any destination.
|


Comments