

A Missing Part of the Modern Data Stack
It's no secret that data warehouses, together with extract, transform, and load (ETL) tools, have become increasingly popular over the past few years. A large part of this popularity is due to the fact that these solutions allow businesses to eliminate data silos and store all their data in a centralized location.
However, one of the drawbacks of data warehouses is that, in most modern data stacks, they are used as a downstream endpoint. Data moves to them unidirectionally from sources and they serve as the final, single source of truth. This is fine for purposes of traditional business intelligence models, which are built around dashboards.
But as data-driven decision-making grows in popularity, the dashboard-centered approach is becoming outdated and, in some cases, might even deter implementation of broader analytics.
From the Data Warehouse Back into Operational Systems
Reverse ETL (or data activation) is the process of sending enriched data from a data warehouse (or other storage) back into operational applications. This allows business teams (e.g. marketing, sales, HR, and finance) to view external data directly in the tools that they actually spend time in, like CRMs, rather than in separate dashboards.
Not only does this make the data easier to view, it can help improve the accuracy of data already in operational applications. It can also provide users with near-real-time access to data.
And finally, it can help to reduce the overall cost of ownership of a data warehouse by making the insights that come from it more useful and accessible, as well as by growing the data analytics culture within a company.
Where Does the Term Reverse ETL Come From?
While ETL is the process of extracting, transforming, and loading data from cloud services into some centralized storage or dashboarding app, reverse ETL is the process of sending data from a centralized storage back into operational systems. In other words, in reverse ETL, the data warehouse is the source rather than the destination.
The term "reverse ETL" is therefore a bit of a misnomer because there is no "T" (i.e. transformation) in the reverse ETL process; the transformations take place before the process begins. Plus, it doesn't really describe what the process does, which is "activate" data by making it "live" in other applications.
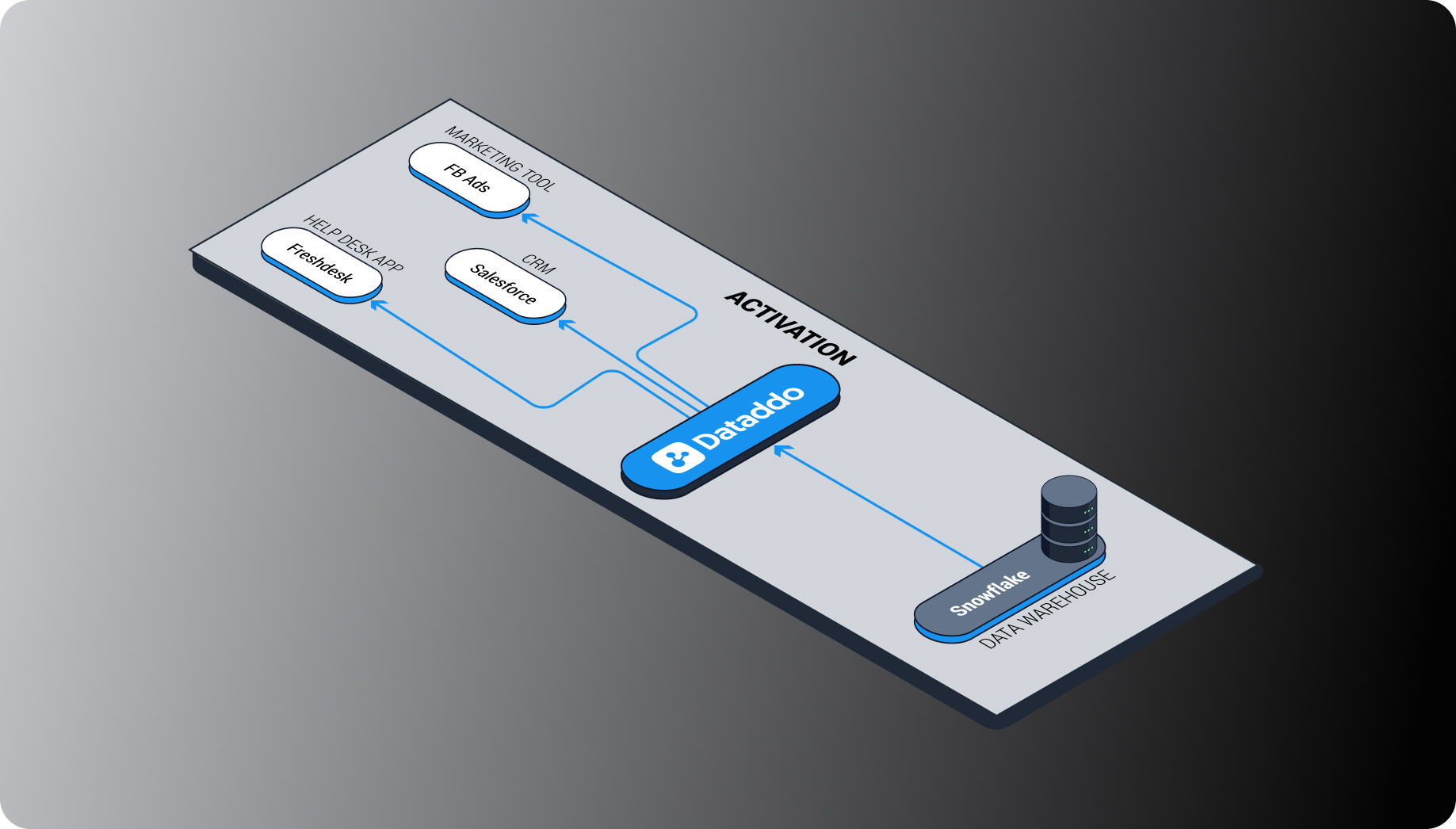
Marketers can activate data by sending segments to their tools for automated, targeted advertising. Sales professionals can activate data by sending it to their CRMs for a better understanding of customers. Customer service professionals can activate data by sending it to their helpdesk apps for a better understanding of which customers are at risk of churn. We therefore believe that a much better term for the process is "data activation."
Nevertheless, the "term reverse ETL" has been around for long enough that it is most likely here to stay.
What Are the Real-World Use Cases of Reverse ETL?
Although reverse ETL is quite a new addition to the modern data stack, there are already some strong use cases emerging on the market.
Enriching Customer Data in CRMs
One of the most common use cases for reverse ETL is keeping CRM data up-to-date and enriched with the latest data from the warehouse. This might include customer profile information, such as job title or income, or the latest purchase history.
Oftentimes, CRM systems have limited logic for computing advanced customer scoring models, lifetime values, and segmentations. But by leveraging the advanced transformation capabilities of cloud data warehouses to perform such computations, and then transferring data back into a CRM via reverse ETL, these limitations can be overcome.
This might also help cut CRM costs because access to the additional computation logic that CRMs do offer often involves pricey upgrades, and is often still insufficient.
Updating Product Information in eCommerce Platforms
Another popular use case is updating product information in ecommerce platforms. This could mean keeping pricing up to date or automatically displaying new products that might be of interest to a customer. For example, if a customer buys or is interested in a product on your website, you might want to show them similar products to boost that customer's lifetime value.
This might sound straightforward, but ecommerce platforms often do not have sufficient capabilities to accurately deploy such logic, especially when inputs from other systems are needed for proper segmentation. Just like with CRMs, sales and product data can be loaded first into a data warehouse where transformations are performed, and then synced back to the ecommerce platform with segmentation data.
Updating Data in ERP Systems
Another use case for reverse ETL is updating data in ERP systems. For example, using reverse ETL to send inventory data from a data warehouse back into an ERP system would make it easier for a company to track inventory across tools.
Marketing Automation
Marketing automation is a powerful use case for reverse ETL, as it allows companies to send customer purchase data, for example, from a warehouse back into any marketing automation tools. This would enable the automatic display of ads to qualified prospects, or the automatic sending of targeted emails to customers based on their purchase history.
How Does Reverse ETL Differ from Event-Based Message Bus Architectures?
Event-based message bus data integration—often associated with traditional enterprise vendors like Tibco, as well as lighter-weight no-code solutions like Zapier, IFTT, and Celigo—is similar to reverse ETL in that it allows you to send data to operational applications. It can also be used to achieve similar results.
However, there are some key differences between the two.
First, event-based architectures are typically used for streaming data, whereas reverse ETL is typically used for batch data. Second, event-based architectures are typically used to send data in real time, whereas reverse ETL can be used to send data on a schedule (e.g. daily, weekly, etc.). Finally, event-based architectures are typically used to distribute and synchronize data between multiple applications and third-party systems, whereas reverse ETL is typically used to send data from a single source (a data warehouse or lake).
When to Use Event-Based Message Busses and When to Use Reverse ETL?
Reverse ETL offers one great advantage over event-based messaging: it allows the transfer of robustly transformed data.
The reverse ETL process involves pulling data from a warehouse, and warehouses allow for all kinds of integrations, aggregations, blending, quality checking, and other heavy computations. Data from multiple sources can be integrated in the message bus architecture pattern, but this is extremely impractical and often leads to very complex and fragile event loops and signal handling.
Message buses should therefore be used for real-time data streaming, where little integration or transformation is needed. Reverse ETL, in contrast, is ideal for batch syncing significantly transformed data.
What Are the Common Challenges When Incorporating Reverse ETL Processes into a Modern Data Stack?
There are several challenges to the implementation of reverse ETL processes. Most are a result of the fact that the target systems are very susceptible to poor quality or inconsistency of incoming data.
Heavy Data Transformation Capability
To effectively leverage reverse ETL, robust data transformations must be performed in a data warehouse. This is essential to ensuring that data is clean and that its models are consistent before it is sent to the target system.
Monitoring, Alerting, and Circuit-Breaking
Setting up proper monitoring and alerts is necessary for quickly identifying and fixing any problems with data that may occur after it has been sent to a target system. Crucial here is the establishment of circuit-breaking policies, i.e. rules that prevent the reverse ETL process from triggering when certain criteria are fulfilled.
The Dataddo platform offers a solution to help solve this problem: automatic data quality checks. These stop the movement of data from business tools when an anomaly or inconsistency is detected.
Defining Processes and Procedures
Defining processes and procedures is necessary to ensure that data is properly managed and controlled throughout its lifecycle.
Despite these challenges, reverse ETL can be a very powerful tool when used correctly. When adopted as part of a modern data stack, it can provide significant benefits to a company.
The Reverse ETL Vendor Landscape
There are currently only a few vendors on the market that offer reverse ETL solutions.
Dataddo
Dataddo is a cloud-based data integration platform that offers bi-directional data flows. One of its key benefits, aside from its fully no-code interface, is the fact that users can simply choose a source, and then send data from that source to any destination—be it an SaaS application, an on-prem database, a cloud data warehouse, a data lake, a BI tool, or a dashboarding application—without worrying about underlying data architecture patterns.
Dataddo supports ETL, ELT, and reverse ETL data flows.
Census
Census is an operational analytics platform that uses reverse ETL to sync data in data warehouses with various SaaS apps. The platform offers a number of features such as data discovery, schema management, and production monitoring.
Hightouch
Hightouch provides a platform that syncs customer data to SaaS apps, as well as marketing, sales, and customer success platforms. The platform also offers features such as customer profile enrichment and event-based triggers.
|
See how Dataddo can help your business Just a few quick steps to get your data to your dashboard for better analysis, without the hassle.
|


Comments