
Many organizations across industries operate production databases in which most of the data does not change very frequently; that is, daily changes and updates only account for a relatively small portion of the overall amount of data stored in them. It is these organizations that can benefit most from change data capture (CDC) data replication.
In this article, I will define CDC data replication, briefly discuss the most common use cases, and then talk about common techniques and the tradeoffs of each. Towards the end, I will give some general implementation insights that I’ve learned as the CEO and founder of data integration company Dataddo.
What Is Change Data Capture (CDC) Data Replication?
CDC data replication is a method of copying data in real or near real time between two databases whereby only newly added or modified data is copied.
It is an alternative to snapshot replication, which involves moving an entire snapshot of one database to another again and again. Snapshot replication may be suitable for organizations that need to preserve individual snapshots of their data over time, but it’s very processing-intensive and leaves a big financial footprint. For organizations that don’t need to do this, CDC can save a lot of paid processing time.
Changes to data can be captured and delivered to their new destination in real time or in small batches (e.g. every hour).
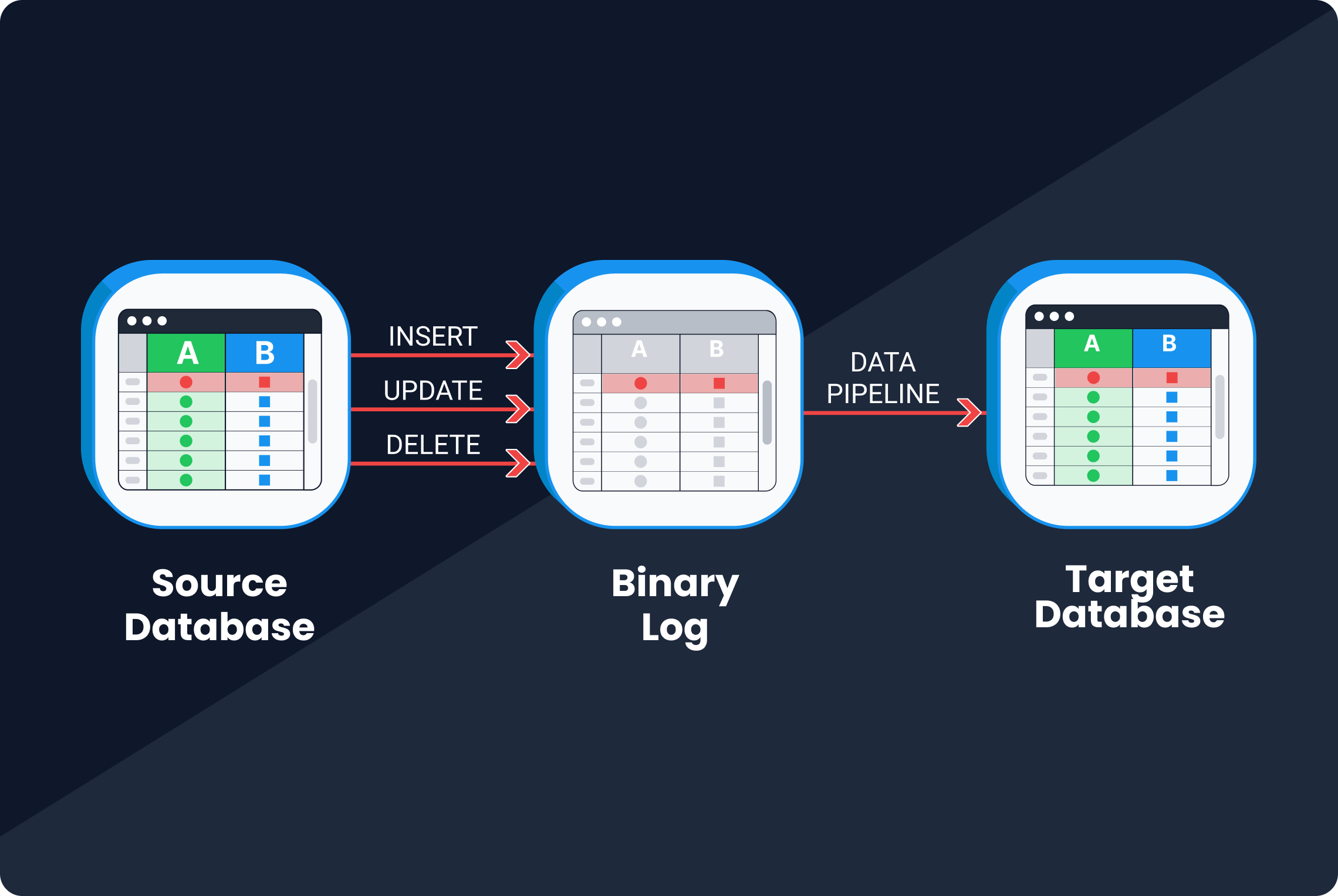 This image illustrates log-based CDC, where the red row is newly added data.
This image illustrates log-based CDC, where the red row is newly added data.
It’s worth mentioning that CDC is not a new process. However, until recently, only large organizations had the engineering resources to implement it. What is new is the growing selection of managed tools that enable it for a fraction of the cost, hence its newfound popularity.
Most Common CDC Use Cases
There’s not enough space in this article to cover all the use cases of CDC data replication, but here are three of the most common.
Data Warehousing for Business Intelligence and Analytics
Any organization that runs a proprietary, data-collecting system is likely to have a production database that stores key info from this system.
Since production databases are designed for write operations, they don’t do much to put data into profitable use. Many organizations will therefore want to copy the data into a data warehouse, where they can run complex read operations for analytics and business intelligence.
If your analytics team needs data in near real time, CDC is a good way to give it to them, because it will quickly deliver the changes to the analytics warehouse as they are made.
Database Migration
CDC is also useful when you are migrating from one database technology to another, and you need to keep everything available in case of downtime. A classic example would be migration from an on-premise database to a cloud database.
Disaster Recovery
Similar to the migration case, CDC is an efficient and potentially cost-effective way to ensure all your data is available in multiple physical locations all the time, in case of downtime in one.
Common CDC Techniques and The Tradeoffs of Each
There are three main CDC techniques, each with its own set of advantages and disadvantages.
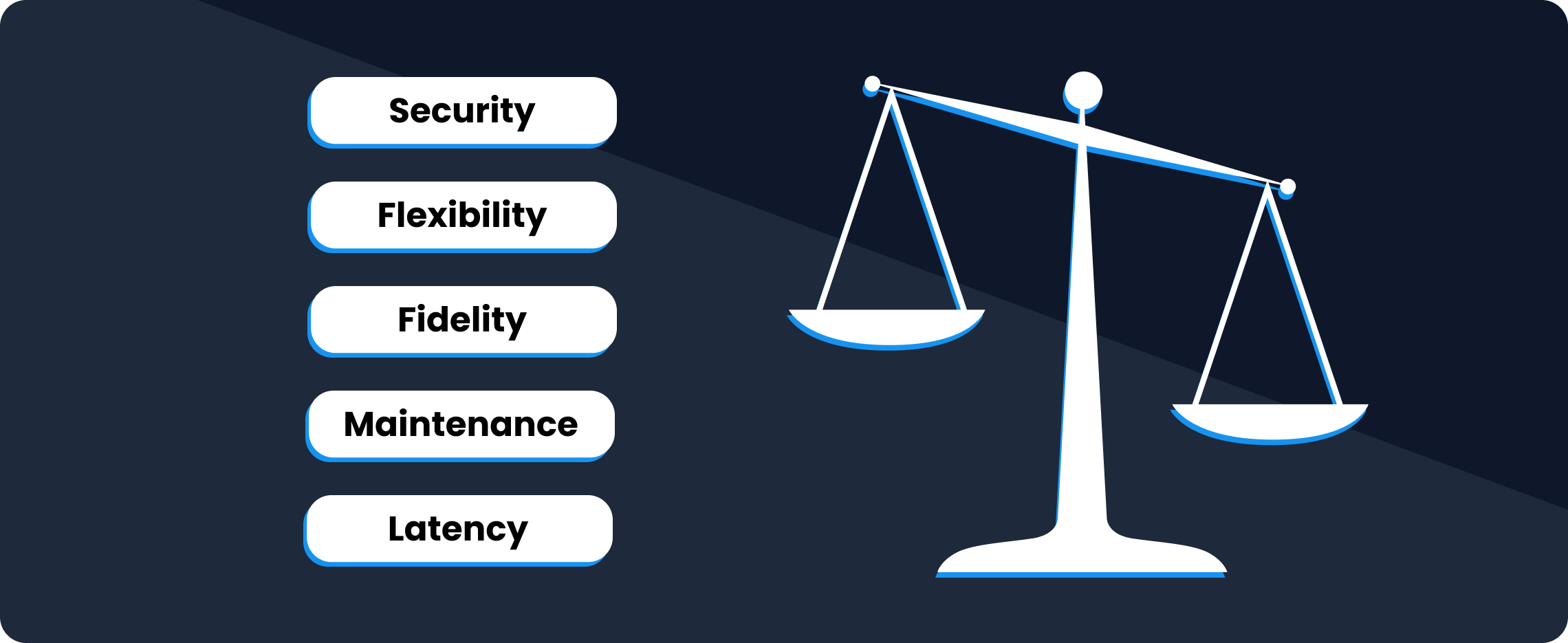 CDC implementation involves tradeoffs between flexibility, fidelity, latency, maintenance, and security.
CDC implementation involves tradeoffs between flexibility, fidelity, latency, maintenance, and security.
Query-Based CDC
Query-based CDC is quite straightforward. All you do with this technique is write a simple select query to select data from a specific table, followed by some condition, like “only select the data that was updated or added yesterday.” Assuming you already have the schema for a secondary table configured, these queries will then take this changed data and produce a new, two-dimensional table with the data, which can be inserted into a new location.
Advantages
- Highly flexible. Allows you to define which changes to capture and how to capture them. This makes it easier to customize the replication process in a very granular way.
- Reduces overhead. Only captures changes that meet specific criteria, so it’s much cheaper than CDC that captures all changes to a database.
- Easier to troubleshoot. Individual queries can easily be examined and corrected in case of any issues.
Disadvantages
- Complex maintenance. Each individual query has to be maintained. If you have a couple hundred tables in your database, for example, you would probably need this many queries as well, and maintaining all of them would be a nightmare. This is the main disadvantage.
- Higher latency. Relies on polling for changes, which can introduce delays in the replication process. This means that you cannot achieve real-time replications using select queries, and that you would need to schedule some kind of batch processing. This may not be much of a problem if you need to analyze something using a long time series, like customer behaviour.
Log-Based CDC
Most database technologies we use today support clustering, meaning you can run them in multiple replicas to achieve high availability. Such technologies must have some kind of binary log, which captures all changes to the database. In log-based CDC, changes are read from the log rather than the database itself, then replicated to the target system.
Advantages
- Low latency. Data changes can be replicated very quickly to downstream systems.
- High fidelity. The logs capture all changes to the database, including data definition language (DDL) changes and data manipulation language (DML) changes. This makes it possible to track deleted rows (which is impossible with query-based CDC).
Disadvantages
- Higher security risk. Requires direct access to the database transaction log. This can raise security concerns, as it will require extensive access levels.
- Limited flexibility. Captures all changes to the database, which limits the flexibility to define changes and customize the replication process. In case of high customization requirements, the logs will have to be heavily post-processed.
In general, log-based CDC is difficult to implement. See the “insights” section below for more information.
Trigger-Based CDC
Trigger-based CDC is kind of a blend between the first two techniques. It involves defining triggers for capturing certain changes in a table, which are then inserted into and tracked in a new table. It is from this new table that the changes are replicated to the target system.
Advantages
- Flexibility. Allows you to define which changes to capture and how to capture them (like in query-based CDC), including deleted rows (like in log-based CDC).
- Low latency. Each time a trigger fires, it counts as an event, and events can be processed in real time or near real time.
Disadvantages
- Extremely complex maintenance. Just like queries in query-based CDC, all triggers need to be maintained individually. So, if you have a database with 200 tables and need to capture changes for all of them, your overall maintenance cost will be very high.
Implementation Insights
As the CEO of a data integration company, I’ve had a lot of experience implementing CDC on scales large and small. Here are a few things I’ve learned along the way.
Different Implementations for Different Logs
Log-based CDC is particularly complex. This is because all logs—e.g., BinLog for MySQL, WAL for Postgres, Redo Log for Oracle, Oplog for Mongo DB—although conceptually the same, are implemented differently. You will therefore need to dive deep into the low-level parameters of your chosen database to get things working.
Writing Data Changes to the Target Destination
You will need to determine how exactly to insert, update, and delete data in your target destination.
In general, inserting is easy, but volume plays a big role in dictating approach. Whether you use batch insert, data streaming, or decide to load changes using a file, you will always face technology tradeoffs.
To ensure proper updating and avoid unnecessary duplicates, you will need to define a virtual key on top of your tables that tells your system what should be inserted and what should be updated.
To ensure proper deleting, you will need to have some failsafe mechanism to make sure that bad implementation won’t cause deletion of all the data in the target table.
Maintaining Long-Running Jobs
If you are transferring only a few rows, things will be quite easy, but if this is the case, then you probably don’t need CDC. So, in general, we can expect CDC jobs to take several minutes or even hours, and this will require reliable mechanisms for monitoring and maintenance.
Error Handling
This could be the topic of a separate article altogether. But, in short, I can say that each technology has a different way for how to raise exceptions and present errors. So, you should define a strategy for what to do if a connection fails. Should you retry it? Should you encapsulate everything in the transactions?
Implementing CDC data replication in-house is quite complicated and very case-specific. This is why it hasn’t traditionally been a popular replication solution, and also why it’s hard to give general advice about how to implement it. In recent years, managed tools like Dataddo, Informatica, SAP Replication Server, and others have significantly lowered the barrier to accessibility.
Not for All, Great for Some
As I mentioned at the beginning of this article, CDC has the potential save a lot of financial resources for companies:
- Whose main database consists largely of data that doesn’t frequently change (i.e. daily changes only account for a relatively small portion of the data in them)
- Whose analytics teams need data in near real time
- That don’t need to retain full snapshots of their main database over time
Nevertheless, there are no perfect technological solutions, only tradeoffs. And the same applies to CDC data replication. Those who choose to implement CDC will have to unequally prioritize flexibility, fidelity, latency, maintenance, and security.
*This article was originally published on KD Nuggets.
|
Replicate Data Between Any Two Databases with Dataddo Move your data from any online services to any database, between any two databases, and from any database into any operational applications.
|


Comments