

This is a guest article by Dialpad—an AI-incorporated cloud-hosted unified communications system.
For your organization to operate like a sleek, well-oiled machine, it’s crucial to make the most of the information at your disposal. But what’s the best way of achieving that, when there’s so much new data created every day?
The short answer is to integrate it. This article takes a look at different types of data integration and how they correspond to different stages of organizational data maturity.
But first, let's talk about what data integration actually is and why you should care about it.
What Is Data Integration?
The modern world runs on data. Everything from the call logs kept by a cloud-based phone system for small business right up to planned missions to Mars depends on reliable data.
Most organizations use data generated from a variety of sources. Moreover, different departments deal with diverse types of data, and may need to liaise with client systems, too. If there is a lot of disparate data that isn’t well organized and connected, it can become a problem.
That’s where data integration comes in. The term refers to the process of collecting and combining data from various sources in one place. The data can then be used for analysis, reporting, or feeding back into operational applications.
The Importance of Data Integration for Business Efficiency
There are a number of ways in which data integration helps your business become more efficient:
- Eliminates data silos: It brings your data together and gives you a complete picture of your business.
- Enables data synchronization: Keeping your data consistently updated and synchronized is much more straightforward following successful integration.
- Helps avoid extensive data entry: Ideally, data only needs to be entered once.
- Allows for simplified data backup: Having all the data in one place means an efficient backup process.
- Provides a competitive advantage: All the resources you’re not using to access and work with data in various locations can be focused on other tasks, helping your organization get ahead of the competition.
Different Types of Data Integration
It’s possible to classify data integration procedures in a number of ways. We will consider them in terms of sources and destinations.
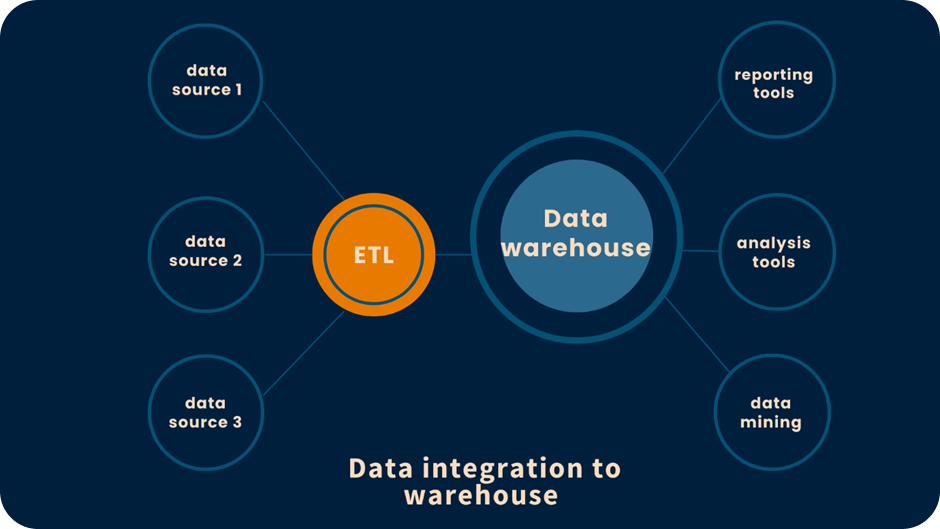
1. App to Dashboard or Data Warehouse/Data Lake (ETL/ELT)
This type of integration is referred to as ETL or ELT (extract, transform, load/extract, load, transform).
In the ETL process, data integration tools are used to pull (extract) data from various sources, automatically clean and harmonize (transform) the data into a common format, then insert (load) the data to either a dashboarding application, or a data warehouse or lake. The ELT process is similar, only the transformation takes place after the data is loaded into a destination.
Synching data directly from online services to dashboarding apps is good for simpler integration cases; for example, when business professionals need quick, ad hoc insights, or when companies are just starting out with data and analytics and want to improve data literacy before investing in a data storage space. Perfect for this is Dataddo’s free integration plan, which lets users integrate data without any code or engineering abilities.
Only ETL tools are capable of syncing data directly to dashboarding apps because, in order to be loaded into such apps, the data must first be transformed (i.e. made “analytics-ready”).
Syncing data to warehouses, lakes, or lakehouses is good for companies at a more advanced stage of data maturity. (This can be done using both ETL and ELT tools.) Storages like these serve as centralized locations where engineers can organize, blend, combine, and modify data in almost any conceivable way. Such storages are crucial for organizations that need to have a “single source of truth.” Once data is processed there, it can be sent back out to other locations for use or stored indefinitely.
So, why use an ELT tool if it can only sync data to storages, while ETL tools can sync data to storages and dashboards?
Well, the fact that ELT tools extract data from storages and load it straight to destinations before any transformations take place makes writing operations more convenient. They are good for companies that need to get all the data now and fast. The catch is, the data won’t be very organized or usable without additional processing by engineers on the back end.
Due to the headaches of building integrations, keeping up with API changes, and performing pipeline maintenance, bespoke, on-premise solutions for this type of data integration are becoming less sustainable by the day. Much more flexible, scalable, and cost-effective are bought solutions.
Popular bought solutions: Dataddo, Fivetran, Mattilion, Supermetrics
2. Database to Database (Data Replication)
It’s fairly common for organizations to have more than one database. But the challenge with this is that, unless data is synched properly between databases, each database becomes its own silo. The solution is data replication.
Databases are replicated for three main reasons.
- Migrating data between storages. Sometimes companies need to swap one database for another as their level of data maturity increases.
- Backing data up. Even with everything in the cloud nowadays, it’s good to have backups (e.g., in case of a security breach).
- Moving data from a central location to smaller “nodes” controlled and operated by line-of-business teams (e.g., marketing, sales, finance) to give them their own data sandbox.
One main challenge with data replication is that each database works a bit differently (e.g., with different schema structures, indexes, data capacity per row/table), so it can be difficult to migrate on a one-to-one basis. In case of #3 above, a major challenge is that line-of-business teams tend not to have the technical expertise necessary to operate node warehouses; so, to make this arrangement work, appropriate training and oversight are essential.
Data replication can only be performed by engineers, and is typically only relevant for more data-mature organizations.
Popular solutions: Dataddo, Fivetran, Matillion, Informatica
3. App to App (Event-Based Messaging)
App-to-app integration, or event-based messaging, is when isolated events are sent from one application directly to another. The data in these events is low-volume, and they are typically sent at a high frequency (real time) by an EMS (event messaging system).
Why would you want to do this?
Imagine you’re using both Stripe and HubSpot, and Stripe acquires some new customer information (address, payment amount, etc.). To give the sales team this new information directly in Hubspot for a better view of this particular customer, the messaging system would take the isolated info (event) from Stripe and pass it there. This is perfect for simpler integration cases and doesn’t require much technical expertise, as EMSs typically have no-code plugins that connect systems.
Together with synchronization of data directly to dashboards, app-to-app messaging is where beginners start integrating their data.
The main drawback of app-to-app messaging is that it’s quite limited. More specifically, the only type of processing you can do is reduction from within the destination app. You cannot enrich or enhance data with data from other apps because it’s always an isolated event (hence the name “event processing”).
Popular solutions: Zapier, IFTTT, Integromat
4. Data Warehouse to App (Reverse ETL)
Data warehouse-to-app integrations overcome the limitations of app-to-app integrations. In contrast to app-to-app, warehouse-to-app syncs are performed at low-to-mid frequencies, volumes are high, and skillful engineering is required for setup.
To illustrate how reverse ETL works, let’s revisit the Stripe/HubSpot example. If you want to give your sales team better insights in Hubspot, you could sync your data from both Stripe and HubSpot to a warehouse. There, your engineers could run complex transformations (blending, computations, etc.) on the data and send a combined load of enriched information back into Hubspot (or any other system) to make insightful information like lifetime value and customer scores readily visible.
To do this with app-to-app integration, you would have to have all kinds of complex routing, which would be so tedious it would defeat its own purpose.
One drawback of reverse ETL is that apps don’t have the kind of failsafe mechanisms that databases do (e.g., no strong system for preventing duplicities), so those in charge of setting up synchronization protocols need to know what they’re doing.
At the moment, there are only a few vendors in this space.
Popular solutions: Dataddo, Census, Hightouch
Final thoughts
Modern organizations of all sizes face challenging decisions in the run of everyday business practice. But the decision to start integrating data should not be a challenging one. As data and analytics continues to become a core business function across industries, companies that don’t start integrating their data may get left in the dust.
That’s why it’s important to take the first step now. It could be something as simple as using a free data integration tool to connect online services to dashboards to get a feel for analytics, or using a no-code EMS to sync important bits of information between systems. Then, once your company starts wanting more from its data, you can start centralizing it in a warehouse, replicating it between warehouses, and sending it back out into operational apps via reverse ETL.
The sky is the limit, but you can’t reach it without taking the first step.
 Jenna Bunnell - Senior Manager, Content Marketing, Dialpad
Jenna Bunnell - Senior Manager, Content Marketing, Dialpad
Jenna Bunnell is the Senior Manager for Content Marketing at Dialpad, an AI-incorporated cloud-hosted unified communications system that provides valuable call details for business owners and sales representatives when they use toll-free numbers from Dialpad.
|
Try Dataddo—A No-Code Data Integration Tool Sync analytics-ready data from any source to any destination in minutes.
|


Comments